こんにちは、MasaKuです。
先日、PostgreSQLの運用知識学習として以下の書籍を読みました。
書籍内で紹介されていた「パーティショニング」について、公式ドキュメントに記載されている内容と照らし合わせて、どのようなケースであればパフォーマンスの向上が見込めるのかを確認してみようと思いました。
なお、PostgreSQL11のパーティショニングについては、弊社のアドベントカレンダーにも掲載されておりますので、あわせてご確認いただけると幸いです。
テーブルのパーティショニングとは
1つのテーブルを複数のテーブルに分割して管理することをテーブルのパーティショニングといいます。
パーティショニングには以下の種類があります。
ショッピングサイトの購入履歴に関するデータ管理方法を例に説明したいと思います。
- レンジ・パーティショニング
指定された範囲の値を基にデータを分散して配置する。
(例: 購入履歴テーブルを1ヶ月単位で分割)

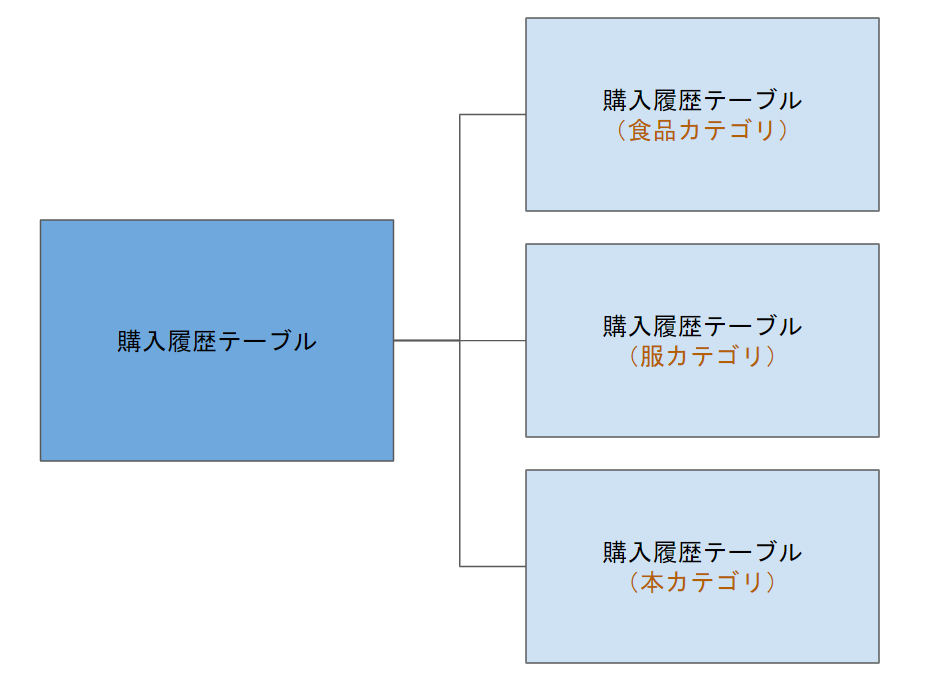
- リスト・パーティショニング
テーブルのキーの値を基にデータを分散して配置する
(例: 商品カテゴリIDによる分割)
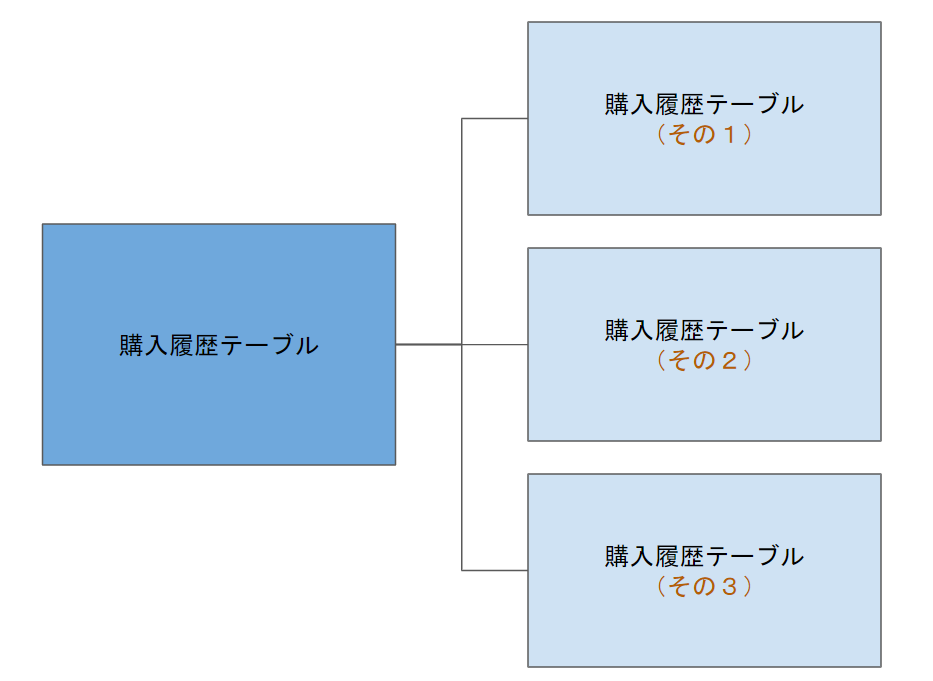
- ハッシュ・パーティショニング(PostgreSQL 11 より)
データの挿入時にカラムのハッシュ値を元に特定のパーティションにデータが偏らないように分散して配置する
(例: レコードIDによる分散)
パーティショニングのメリット
PostgreSQLの公式ドキュメントではパーティショニングのメリットを以下のように説明されています
特定の条件下で問い合わせのパフォーマンスが劇的に向上することがあります。 特にテーブル内のアクセスが集中する行の殆どが単一または少数のパーティションに存在している場合がそうです。 パーティショニングはインデックスの先頭にある列の代わりになり、インデックスの大きさを小さくして、インデックスの頻繁に使われる部分がメモリに収まりやすくなるようにします。
問い合わせや更新が一つのパーティションの大部分にアクセスする場合、インデックスやランダムアクセスを使用してテーブル全体にまたがる読み取りをする代わりに、そのパーティションへの順次アクセスをすることでパフォーマンスを向上させることができます。
一括挿入や削除について、その要件をパーティションの設計に組み込んでいれば、それをパーティションの追加や削除で実現することが可能です。 ALTER TABLE DETACH PARTITIONを実行する、あるいは個々のパーティションをDROP TABLEで削除するのは、一括の操作をするよりも遥かに高速です。 これらのコマンドはまた、一括のDELETEで引き起こされるVACUUMのオーバーヘッドを完全に回避できます。
滅多に使用されないデータを安価で低速なストレージメディアに移行することができます。
今回は、1つ目の利点に着目して動作を確認してみたいと思います。
データの準備
検証のために以下のテーブルを作成しておきます。
-- 商品カテゴリテーブル CREATE TABLE categories( id SERIAL PRIMARY KEY, name TEXT UNIQUE ); -- 商品カテゴリテーブルのサンプルデータ INSERT INTO categories (name) VALUES ('食品'); INSERT INTO categories (name) VALUES ('衣類'); INSERT INTO categories (name) VALUES ('本'); INSERT INTO categories (name) VALUES ('コンピュータ'); -- 購入位履歴テーブル CREATE TABLE purchase( id SERIAL PRIMARY KEY, category_id INTEGER, name TEXT, date TIMESTAMP DEFAULT NOW()), FOREIGN KEY (category_id) REFERENCES categories(id) );
購入履歴テーブルのテストデータは過去5年分で合計50万件とします。
-- 購入履歴テーブルのサンプルデータ INSERT INTO purchase (name, category_id, date) SELECT 'test', TRUNC((RANDOM() * 4 ):: NUMERIC, 0) + 1, '2014-01-01'::DATE + (RANDOM() * 1780)::INTEGER AS date FROM GENERATE_SERIES(1, 500000) ;
パーティショニングで作成するテーブルについては後述します。
実践
文章内にもありますとおり、特定条件下とは「特にテーブル内のアクセスが集中する行の殆どが単一または少数のパーティションに存在している場合」です。
購入履歴を例にして考えてみたいと思います。
あるサービスでは、5年分の購入履歴を保管しているとします。
そのうち、直近1年の購入履歴からオススメ商品を提示する機能を実装する場合、購入履歴を一つのテーブルで管理するよりも、年単位で分割されたテーブルで管理しておくほうがパフォーマンスは向上するようです。
今回のケースでは date カラムをキーとするレンジ・パーティションを行います。
CREATE TABLE purchase_range( id SERIAL, category_id INTEGER, name TEXT, date TIMESTAMP DEFAULT NOW(), FOREIGN KEY (category_id) REFERENCES categories(id) ) PARTITION BY RANGE (date); CREATE TABLE purchase_range_y2014 PARTITION OF purchase_range FOR VALUES FROM ('2014-01-01 00:00:00') TO ('2014-12-31 23:59:59'); CREATE TABLE purchase_range_y2015 PARTITION OF purchase_range FOR VALUES FROM ('2015-01-01 00:00:00') TO ('2015-12-31 23:59:59'); CREATE TABLE purchase_range_y2016 PARTITION OF purchase_range FOR VALUES FROM ('2016-01-01 00:00:00') TO ('2016-12-31 23:59:59'); CREATE TABLE purchase_range_y2017 PARTITION OF purchase_range FOR VALUES FROM ('2017-01-01 00:00:00') TO ('2017-12-31 23:59:59'); CREATE TABLE purchase_range_y2018 PARTITION OF purchase_range FOR VALUES FROM ('2018-01-01 00:00:00') TO ('2018-12-31 23:59:59'); -- 購入履歴テーブルサンプルデータ(パーティション) INSERT INTO purchase_range (name, category_id, date) SELECT 'test', TRUNC((RANDOM() * 4 ):: NUMERIC, 0) + 1 AS category_id, '2014-01-01'::DATE + (RANDOM() * 1780)::INTEGER AS date FROM GENERATE_SERIES(1, 500000) ;
パーティションのキーを用いた検索の場合
まずは、2017年12月の購入履歴の件数を取得するSQLを実行した結果を見てみましょう。
-- 単一テーブルで管理されている場合 explain analyze select count(*) from purchase where date > '2017-12-01' and date < '2017-12-31'; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=6114.90..6114.91 rows=1 width=8) (actual time=125.218..125.218 rows=1 loops=1) -> Gather (cost=6114.69..6114.90 rows=2 width=8) (actual time=120.538..125.274 rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (cost=5114.69..5114.70 rows=1 width=8) (actual time=96.651..96.652 rows=1 loops=3) -> Parallel Seq Scan on purchase (cost=0.00..5108.41 rows=2513 width=0) (actual time=0.036..96.162 rows=2053 loops=3) Filter: ((date > '2017-12-01 00:00:00'::timestamp without time zone) AND (date < '2017-12-31 00:00:00'::timestamp without time zone)) Rows Removed by Filter: 100529 Planning Time: 0.215 ms Execution Time: 125.323 ms -- パーティションで分割しているテーブルの場合 explain analyze select count(*) from purchase_range where date > '2017-12-01' and date < '2017-12-31'; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=26.09..26.10 rows=1 width=8) (actual time=0.007..0.007 rows=1 loops=1) -> Append (cost=0.00..26.07 rows=5 width=0) (actual time=0.004..0.004 rows=0 loops=1) -> Seq Scan on purchase_range_y2017 (cost=0.00..26.05 rows=5 width=0) (actual time=0.003..0.003 rows=0 loops=1) Filter: ((date > '2017-12-01 00:00:00'::timestamp without time zone) AND (date < '2017-12-31 00:00:00'::timest amp without time zone)) Planning Time: 0.667 ms Execution Time: 0.034 ms
実行時間はパーティションで分割しているテーブルの方が短くなるという結果になりました。
日時でパーティションを分割しているため、対象外の期間のレコードにはアクセスされないためパフォーマンスが向上しました。
全体検索の場合
今度は、全データの件数を取得する場合を考慮してみました。
-- 単一テーブルで管理されている場合 explain analyze select count(*) from purchase; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=6789.38..6789.39 rows=1 width=8) (actual time=274.970..274.970 rows=1 loops=1) -> Gather (cost=6789.17..6789.38 rows=2 width=8) (actual time=273.169..275.097 rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (cost=5789.17..5789.18 rows=1 width=8) (actual time=252.091..252.092 rows=1 loops=3) -> Parallel Seq Scan on purchase (cost=0.00..5268.33 rows=208333 width=0) (actual time=0.016..105.048 rows=166667 loops=3) Planning Time: 0.135 ms Execution Time: 275.149 ms -- パーティションで分割しているテーブルの場合 explain analyze select count(*) from purchase_parent; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=8690.90..8690.91 rows=1 width=8) (actual time=429.425..429.425 rows=1 loops=1) -> Gather (cost=8690.68..8690.89 rows=2 width=8) (actual time=429.415..429.608 rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (cost=7690.68..7690.69 rows=1 width=8) (actual time=406.901..406.901 rows=1 loops=3) -> Parallel Append (cost=0.00..7169.85 rows=208334 width=0) (actual time=0.018..269.589 rows=166667 loops=3) -> Parallel Seq Scan on purchase_y2017 (cost=0.00..1259.81 rows=60481 width=0) (actual time=0.015..90.205 rows=102817 loops=1) -> Parallel Seq Scan on purchase_y2015 (cost=0.00..1259.19 rows=60419 width=0) (actual time=0.017..112.477 rows=102713 loops=1) -> Parallel Seq Scan on purchase_y2016 (cost=0.00..1257.65 rows=60365 width=0) (actual time=0.016..18.776 rows=34207 loops=3) -> Parallel Seq Scan on purchase_y2014 (cost=0.00..1255.53 rows=60253 width=0) (actual time=0.014..61.613 rows=51215 loops=2) -> Parallel Seq Scan on purchase_y2018 (cost=0.00..1096.00 rows=52600 width=0) (actual time=0.019..76.853 rows=89420 loops=1) Planning Time: 0.162 ms Execution Time: 429.668 ms
ある意味予想通りでしたが、実行時間はパーティショニングしているテーブルのほうが長くなりました。
テーブルを分割しているために、本来一度で完了するシーケンシャルスキャンがパーティションの数だけ実行されるため、パフォーマンスが劣化したと思われます。
購入履歴を検索する、ということに主眼を置く場合は、運用方法次第ではパーティショニングが必ずしも適切ではない場合もあるので注意が必要です。
パーティション分割のキー以外の検索の場合
最後に、パーティション分割に利用したキー以外のカラムを絞込み条件にした場合のパフォーマンスを確認してみます。
今回はカテゴリIDを対象にした検索を行ってみたいと思います。
-- 単一テーブルで管理されている場合 explain analyze delete from purchase where category_id = 1378; QUERY PLAN ------------------------------------------------------------------------------------------------------------- Delete on purchase (cost=0.00..7031.81 rows=1 width=6) (actual time=87.803..87.803 rows=0 loops=1) -> Seq Scan on purchase (cost=0.00..7031.81 rows=1 width=6) (actual time=87.801..87.801 rows=0 loops=1) Filter: (category_id = 1378) Rows Removed by Filter: 307745 Planning Time: 0.062 ms Execution Time: 87.829 ms -- パーティションで分割しているテーブルの場合 explain analyze delete from purchase_range where category_id = 1378; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Delete on purchase_range (cost=0.00..7869.12 rows=5 width=6) (actual time=103.825..103.826 rows=0 loops=1) Delete on purchase_range_y2014 Delete on purchase_range_y2015 Delete on purchase_range_y2016 Delete on purchase_range_y2017 Delete on purchase_range_y2018 -> Seq Scan on purchase_range_y2014 (cost=0.00..1614.14 rows=1 width=6) (actual time=22.576..22.576 rows=0 loops=1) Filter: (category_id = 1378) Rows Removed by Filter: 76811 -> Seq Scan on purchase_range_y2015 (cost=0.00..1612.55 rows=1 width=6) (actual time=21.112..21.112 rows=0 loops=1) Filter: (category_id = 1378) Rows Removed by Filter: 76844 -> Seq Scan on purchase_range_y2016 (cost=0.00..1627.21 rows=1 width=6) (actual time=20.850..20.850 rows=0 loops=1) Filter: (category_id = 1378) Rows Removed by Filter: 77537 -> Seq Scan on purchase_range_y2017 (cost=0.00..1603.49 rows=1 width=6) (actual time=21.146..21.146 rows=0 loops=1) Filter: (category_id = 1378) Rows Removed by Filter: 76279 -> Seq Scan on purchase_range_y2018 (cost=0.00..1411.74 rows=1 width=6) (actual time=18.105..18.106 rows=0 loops=1) Filter: (category_id = 1378) Rows Removed by Filter: 67099 Planning Time: 0.376 ms Execution Time: 103.901 ms
多少の差があるもののそこまで大きな差がないという、少し意外な結果となりました。
というのも、今回作成したサンプルデータは日付でパーティショニングしているため、カテゴリIDで絞り込んだ場合は分散配置しているテーブルすべてをチェックしなければならなくなります。
そのため、先ほどの全体検索と同程度のパフォーマンスになると思っていました。
パーティションで分割されているテーブルの数や、1テーブルに格納されているレコードの量によって差が出るのではないでしょうか。
おわりに
パーティショニングといっても、データ管理の銀の弾丸というものではなく、場合によってはパフォーマンスが劣化する場合があることがわかりました。
今回はレンジパーティションを例にしましたが、実際のサービスがどのように運用されていくかを考慮することで、どのようにパーティションを分割すべきかが見えてくるのではないでしょうか。 (もしくは、パーティション分割する必要が無いことも)
その他にも、継承パーティショニングの検証や、高負荷状態でのパフォーマンスなど、検証してみたいことがありましたが、その辺はまた別の機会にしたいと思います。
参考サイト
[改訂新版]内部構造から学ぶPostgreSQL 設計・運用計画の鉄則:書籍案内|技術評論社
第1回「テーブル・パーティショニングが大幅アップデート」 | NTTデータ先端技術株式会社
PostgreSQL 11先行紹介 - パーティション機能のさらなる改善 | NTTテクノクロスブログ
PostgreSQL11のパーティショニングを試してみる - Qiita
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
forms.gleイベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください! rakus.connpass.com
