デベロッパーのkyosimotoです。
Ansibleをバージョンアップ作業の自動化ツールとして導入するための手順、おすすめ構成などについて紹介させていただきます。
目次
なぜAnsible
私は担当サービスのバージョンアップ作業を自動化するため、シェルベースのスクリプトを開発・運用してきました。
スクリプト導入により、ほとんどの作業は自動化され、運用コストは大幅に削減されました。
半面、バージョンアップスクリプトの属人化が課題となっており、リリース時のトラブルが起きた場合に、作業担当者による
原因調査と復旧作業が難しい状態となっています。
シェルスクリプトで作成したバージョンアップスクリプトには、フレームワークのような拘束力が無く、長い運用の中でイレギュラーケースに対応したコードやフラグが追加され、複雑化の道をすすみ続ける可能性があります。
さらには、今のところこの複雑化したスクリプトをポジティブに学習したいという人はいません。問題が起きたとしても、開発担当者に聞けばすぐに解決できるからです。
私は属人化を解消するためには、シェルスクリプトによる実装をやめ、学習コストが低く複雑なコードを生まない自動化ツールの導入が必要と考えており、この要件にマッチしたAnsibleを導入提案することになりました。
どんな感じ?
今のところメリットと感じているのは下記3点です。
学習コストが低い
設定ファイルはYAMLという形式で記述します。設定ファイルがシンプルで、初めての人でも内容をすぐに理解できると思います。
運用作業用のモジュールが充実していますので、プログラミング書くことも読むこともほとんどありません。
導入コストが低い
管理対象サーバには余計なツールやデーモンをインストールする必要がありません。
SSHとPythonさえ使えれば、Ansibleからの操作が可能ですので、運用チームへも提案しやすいと思います。
運用コストが低い
少しの工夫で設定ファイルをそのまま手順書として扱うことができます。
Ansibleの基本
実行方法
Ansibleの実行コマンドは以下の通りです。
$ ansible-playbook -i {Inventory} {Playbook}
Inventoryには、サーバ名やIPアドレスなどの管理対象ノードの情報、Playbookには管理対象ノードで実行するタスクを記述します。
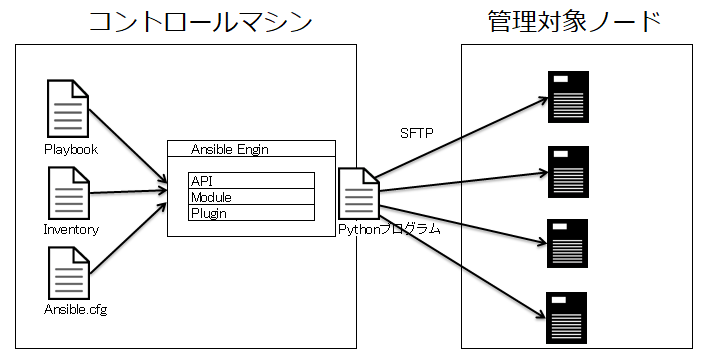
実行イメージ
Ansibleは、上記コマンドを実行するとPlaybookの内容をPythonのプログラムに変換します。
変換されたプログラムファイルは、Inventory(インベントリ)に記述された管理対象ノードに転送後に実行されます。
マシン要件
ファイル構成
私のお勧めするファイル構成サンプルを紹介します。
myapp_verup
product.ini
staging.ini
development.ini
versionup.yml
roles/
apacheを停止する/
apacheを起動する/
apacheをバージョンアップする/
cronを停止する/
cronを起動する/
postgresqlを停止する/
postgresqlを起動する/
postgresqlをバージョンアップする/
アプリケーションをバージョンアップする/
playbook(サンプル)
以下、playbookファイルの内容です。
- myapp_verup/versionup.yml
---
- hosts: all
roles:
- cronを停止する
- hosts: webservers
roles:
- apacheを停止する
- apacheをバージョンアップする
- phpをバージョンアップする
- アプリケーションをバージョンアップする
- hosts: dbservers
roles:
- postgresqlを停止する
- postgresqlをバージョンアップする
- postgresqlを起動する。
- hosts: webservers
roles:
- apacheを起動する
- hosts: all
roles:
- cronを起動する
ファイル構成のポイント
ファイル構成を考える上で、お勧めするポイントは下記2点です。
playbookを日本語で記述する
playbookのタスクを日本語化することで、設定ファイルの可読性が上がる、playbookがそのまま手順書/ドキュメントになるという点でメリットが大きいと考えています。
バージョンアップ作業に集中する。
バージョンアップ作業以外のタスクを含めないようにします。
例えば、サーバ構成管理や冪等性のための実装を行うと、Ansibleの設定は複雑化します。
複雑化は属人化を進行させますし、(Serverspecなど)ツールを使ったテストなども検討する必要がでてくるでしょう。
検証環境の準備
ここからは、Ansibleの検証用環境の構築手順について記載します。
検証環境の説明
仮想マシンの構築に Vagrant + Virtualbox を利用します。
検証用に構築するサーバは以下の通りです。
| ホスト名 |
IPアドレス |
OS |
MW/Tool |
| control |
192.168.33.100 |
CentOS 6.9 |
Ansible |
| web |
192.168.33.101 |
CentOS 6.9 |
Apache2.2 + PHP7.1 |
| db |
192.168.33.102 |
CentOS 6.9 |
PostgreSQL9.6 |
別のディストリビューションで検証したい場合は、Vagrant Cloudよりboxイメージを検索し、後述する「vagrant init」コマンドの引数に指定してください。
$ cd
$ mkdir -p vagrant_work/ansible_test
$ cd vagrant_work/ansible_test
$ vagrant init bento/centos-6.9
$ vi Vagrantfile
-----
config.vm.define "control" do |node|
node.vm.box = "bento/centos-6.9"
node.vm.hostname = "control"
node.vm.network :private_network, ip: "192.168.33.100"
end
config.vm.define "web" do |node|
node.vm.box = "bento/centos-6.9"
node.vm.hostname = "web"
node.vm.network :private_network, ip: "192.168.33.101"
end
config.vm.define "db" do |node|
node.vm.box = "bento/centos-6.9"
node.vm.hostname = "db"
node.vm.network :private_network, ip: "192.168.33.102"
end
-----
$ vagrant up
仮想サーバにSSH接続する
$ vagrant ssh control
Windowsの場合は、ターミナルソフトで接続します。
Ansible実行環境の構築
AnsibleのインストールとSSH設定の手順について記載します。
Ansibleのインストール
$ vagrant ssh control
$ sudo yum install -y epel-release
$ sudo yum install -y ansible
$ ansible --version
ansible 2.3.2.0
config file = /etc/ansible/ansible.cfg
configured module search path = Default w/o overrides
python version = 2.6.6 (r266:84292, Aug 18 2016, 15:13:37) [GCC 4.4.7 20120313 (Red Hat 4.4.7-17)]
接続先サーバへのSSH接続を簡単にするためSSH設定を記述します。
$ vi ~/.ssh/config
------------
Host *
StrictHostKeyChecking no
UserKnownHostsFile=/dev/null
Host web
HostName 192.168.33.101
User vagrant
Host db
HostName 192.168.33.102
User vagrant
------------
# 設定ファイルのパーミッションを変更します。
$ vi ~/.ssh/config
------------
Host *
StrictHostKeyChecking no
UserKnownHostsFile=/dev/null
Host web
HostName 192.168.33.101
User vagrant
Host db
HostName 192.168.33.102
User vagrant
------------
# 設定ファイルのパーミッションを変更します。
$ chmod 600 ~/.ssh/config
# SSHの公開鍵を登録します。
$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/vagrant/.ssh/id_rsa): # Enterキー入力
Enter passphrase (empty for no passphrase): # Enterキー入力
Enter same passphrase again: # Enterキー入力
Your identification has been saved in /home/vagrant/.ssh/id_rsa.
Your public key has been saved in /home/vagrant/.ssh/id_rsa.pub.
The key fingerprint is:
# 秘密鍵と公開鍵が作成されます。
~/.ssh/id_rsa
~/.ssh/id_rsa.pujb
# 作成したSSH公開鍵を接続先サーバにコピーします。
$ ssh-copy-id web
# パスワードは「vagrant」
$ ssh-copy-id db
# パスワードは「vagrant」
# 接続先サーバにパスワードなしでアクセスできることを確認します。
$ ssh web
$ hostname
web
$ exit
$ ssh db
$ hostname
db
$ exit
バージョンアップ手順の検証用に、予めミドルウェアをセットアップします。
WEBサーバの構築 (Apache2.2 + PHP7.1)
$ ssh web
$ sudo yum install -y httpd
$ sudo yum install -y epel-release
$ sudo rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm
$ sudo yum -y --enablerepo=remi-php71,epel install php php-cli php-common php-mbstring php-mcrypt php-pdo php-xml php-json php-devel php-pecl-zip php-pgsql
$ sudo service httpd restart
$ sudo chkconfig httpd on
$ sudo vi /var/www/html/phpinfo.php
--------------
<?php
phpinfo();
--------------
$ exit
DBサーバの構築(PostgreSQL9.6)
$ ssh db
$ sudo yum install -y https://yum.postgresql.org/9.6/redhat/rhel-6.9-x86_64/pgdg-redhat96-9.6-3.noarch.rpm
$ sudo yum -y install postgresql96-server
$ sudo service postgresql-9.6 initdb
$ sudo vi /var/lib/pgsql/9.6/data/pg_hba.conf
--------------
host all all 192.168.33.101/32 trust
--------------
$ sudo vi /var/lib/pgsql/9.6/data/postgresql.conf
--------------
listen_addresses = '*'
--------------
$ sudo service postgresql-9.6 start
$ sudo chkconfig postgresql-9.6 on
$ sudo su - postgres -c "psql"
> \c test
> create database test;
> create table t_staff (id int, name text);
> insert into t_staff values (1, 'あああああ'), (2, 'いいいいい');
> \q
$ exit
WEB/DBサーバの連携チェック
$ ssh web
$ sudo vi /var/www/html/test.php
---------
<?php
$connectString = "host=192.168.33.102 port=5432 dbname=test user=postgres";
$conn = pg_connect($connectString);
$result = pg_query($conn, "select * from t_staff");
var_dump(pg_fetch_all($result));
---------
http://192.168.33.101/test.php
ファイル構成の項目で紹介したAnsibleプロジェクトを作成していきましょう。
バージョンアッププロジェクト用のディレクトリ作成
$ mkdir ~/myapp_verup
$ cd ~/myapp_verup
$ mkdir -p roles/apacheを停止する/tasks
$ mkdir -p roles/apacheを起動する/tasks
$ mkdir -p roles/apacheをバージョンアップする/tasks
$ mkdir -p roles/cronを停止する/tasks
$ mkdir -p roles/cronを起動する/tasks
$ mkdir -p roles/postgresqlを停止する/tasks
$ mkdir -p roles/postgresqlを起動する/tasks
$ mkdir -p roles/postgresqlをバージョンアップする/tasks
$ mkdir -p roles/アプリケーションをバージョンアップする/tasks
Inventoryの作成
Inventoryでは、管理対象ノードのホスト名、またはIPアドレスとグループの定義を行います。
ファイルはINIファイル形式で記述します。
- myapp_verup/development.ini
[webservers]
192.168.33.101
[dbservers]
192.168.33.102
Inventoryの作成(補足)
Inventoryを本番環境用、ステージング環境用、開発環境用に分けて管理することで
バージョンアップ対象の切り替えできるようにします。
以下サンプルです。
- myapp_verup/product.ini (本番環境用)
[webservers]
192.168.34.101
192.168.34.102
192.168.34.103
[dbservers]
192.168.34.104
192.168.34.105
- myapp_verup/staging.ini (ステージング環境用)
[webservers]
192.168.35.101
192.168.35.102
192.168.35.103
[dbservers]
192.168.35.104
192.168.35.105
Playbookの作成
Playbookには、バージョンアップ手順を記述します。
(どのサーバでどんなタスクをどのような順番で実行するかを記述します)
- myapp_verup/versionup.yml
---
- hosts: all
roles:
- cronを停止する
- hosts: webservers
roles:
- apacheを停止する
- apacheをバージョンアップする
- phpをバージョンアップする
- アプリケーションをバージョンアップする
- hosts: dbservers
roles:
- postgresqlを停止する
- postgresqlをバージョンアップする
- postgresqlを起動する
- hosts: webservers
roles:
- apacheを起動する
- hosts: all
roles:
- cronを起動する
ファイルはYAML形式となりますので、拡張子は「yml」、1行目は「---」としてください。
2行目以降にバージョンアップ手順を記述します。書き方のルールは以下の通りです。
| セクション |
解説 |
| hosts |
inventoryに定義したグループ名を記述します。
"all"の場合、inventoryに記述した全サーバを対象に処理を実行します。 |
| roles |
hostsセクションに指定したサーバで実行するタスクを記載します。
タスクは「◯◯を停止する」「◯◯を起動する」「◯◯をバージョンアップする」くらいの粒度で記述しておき、具体的な処理内容をroles配下のタスク名と同名のディレクトリ配下に実装します。 |
ansible.cfgの作成
Ansibleの動作設定を記述するファイルで、INI形式で記述します。
- myapp_verup/ansible.cfg
[defaults]
log_path=/tmp/ansible.log
[privilege_escalation]
become = true
become_user = root
Roleの作成
Playbookのrolesディレクティブに記述したタスクの実態をrolesディレクトリの配下作成します。
例えば、「Cronを起動する」というタスクは、roles/Cronを起動する/tasks/main.yml に、処理内容を記述します。
service コマンドが準備されているミドルウェア(デーモン)であれば、「service」モジュールを使って以下のように記述します。
- myapp_verup/roles/cronを起動する/tasks/main.yml
---
- name: crondを起動する
service:
name: crond
state: started
- myapp_verup/roles/apacheを起動する/tasks/main.yml
---
- name: Apacheを起動する
service:
name: httpd
state: started
---
- name: PostgreSQLを起動する
service:
name: postgresql-9.6
state: started
※「service」モジュールの使い方はこちら
service コマンドが提供されていないミドルウェアの場合は、「shell」モジュールと「wait_for」モジュールで実装することもできます。
---
- name: 起動コマンドを実行する
shell: /usr/local/myapp/apache/bin/apachectl start
- name: 80番ポートの疎通確認が終わるまで待機する
wait_for:
host: localhost
port: 80
state: started
delay: 1
timeout: 60
shell モジュールは終了ステータスコードが0以外は、すべてエラーとして処理を中断しますので注意が必要です。
ステータスコードが0以外でも処理を継続する場合には、下記サンプルを参考にしてください。
---
- name: スクリプトを実行する
shell: /usr/local/myapp/bin/hoge.sh
register: exitStatus
failed_when: exitStatus.rc not in [0, 100]
※「shell」モジュールの使い方はこちら
※「wait_for」モジュールの使い方はこちら
service コマンドが準備されているミドルウェア(デーモン)であれば、「service」モジュールを使って以下のように記述します。
- myapp_verup/roles/cronを停止する/tasks/main.yml
---
- name: crondを停止する
service:
name: crond
state: stopped
- myapp_verup/roles/apacheを停止する/tasks/main.yml
---
- name: Apacheを停止する
service:
name: httpd
state: stopped
---
- name: PostgreSQLを停止する
service:
name: postgresql-9.6
state: stopped
RPMがyumコマンドでバージョンアップできる場合は、「yum」モジュールを利用して「latest」の状態に更新します。
- myapp_verup/roles/apacheをバージョンアップする/tasks/main.yml
---
- name: RPMを更新する
yum:
name: httpd
state: latest
- myapp_verup/roles/phpをバージョンアップする/tasks/main.yml
---
- name: RPMを更新する
yum:
name={{ item }}
state=latest
enablerepo=remi,epel
with_items:
- php
- php-cli
- php-common
- php-mbstring
- php-mcrypt
- php-pdo
- php-xml
- php-json
- php-devel
- php-pecl-zip
- php-pgsql
- myapp_verup/roles/postgresqlをバージョンアップする/tasks/main.yml
---
- name: RPMを更新する
yum:
name=postgresql96-server
state=latest
リポジトリ管理されていない(カスタムRPMをつかっている)場合は、以下設定を参考にしてください。
myapp_verup
└ roles
└ Apacheをバージョンアップする
├ tasks
│ └ main.yml
├ files
│ └ myapp_apache2.2.99.rpm
├ templates
│ └ httpd.conf.j2
└ vars
└ main.yml
※ディレクトリ構成については公式ページのBest Practices の「Directory Layout」を参考にしています。
- myapp_verup/roles/Apacheをバージョンアップする/tasks/main.yml
---
- name: RPMファイルを転送する
copy: src=files/{{ rpm_file_name }} dest=/tmp
- name: RPMファイルの状態を取得する
stat:
path: /tmp/{{ rpm_file_name }}
register: file_status
- name: チェックサム値を確認する
fail: msg='MD5 value did not match'
when: file_status.stat.md5 != rpm_file_md5
- name: "RPMを更新する ({{ rpm_file_name }})"
shell: rpm -Uvh --force --nodeps /tmp/{{ rpm_file_name }}
args:
chdir: "/tmp"
register: verup_result
- name: ステータスコードを確認する
fail: msg="Failed upgrade rpm."
when: verup_result.rc != 0
- name: httpd.confを差し替える
template:
src=httpd.conf.j2
dest=/usr/local/vanguard/apache/conf/httpd.conf
owner=root
group=root
mode=644
※「copy」モジュールの使い方はこちら
※「stat」モジュールの使い方はこちら
※「fail」モジュールの使い方はこちら
※「template」モジュールの使い方はこちら
- myapp_verup/roles/Apacheをバージョンアップする/templates/httpd.conf.j2
...中略...
ServerName {{ apache_server_name }}:80
...中略...
※ 上記変数部分は、例えばInventoryファイルに記述した変数の値に自動で
置き換えることができます。
...中略...
[web:vars]
apache_server_name = myapp.example.com
...中略...
- myapp_verup/roles/Apacheをバージョンアップする/vars/main.yml
---
rpm_file_name: "vg_httpd-2.4.25-centos6.x86_64.rpm"
rpm_file_md5: "4f8009b1cbcf5dbc7f082773d2f0d661"
playbookの実行
$ cd ~/myapp_verup
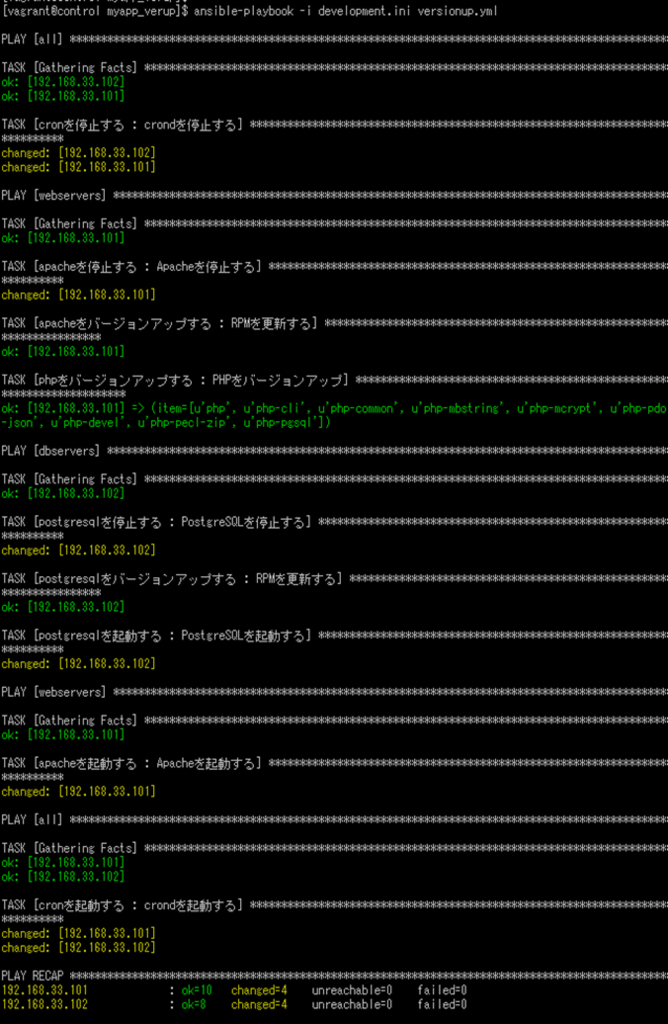
$ ansible-playbook -i development.ini versionup.yml
実行結果は以下の通りです。
日本語で書いたタスクがそのままターミナル上のログに出力されていることが確認できます。
(/tmp/ansible.log にも出力されます。)
最後に
本記事は、運用チーム向けにAnsibleを使ったバージョンアップ自動化提案後に書いた記事です。
本番運用が開始されれば、いろいろと課題はでてくると思いますので、知見がたまりましたら
改めて情報を共有させていただこうと思います。
以上、ありがとうございました。






")
")

")









