3月初旬に開催されたJaSST'18の参加レポートです。 [読了時間 8分]
JaSST Tokyo とは
国内最大級のソフトウェアテストシンポジウムです。
JaSST'18 Tokyo
- ソフトウェアテストシンポジウム 2018 東京
- 日時 : 2018/03/07水~08木
- 場所 : 東京都 千代田区 日本大学理工学部 駿河台校舎1号館
- 参加者 : 1600人
- 参加費 : 2日券(早割) 8,400円
JaSST Tokyo の昨年と今年のベストスピーカ―賞の傾向(2017年、2018年)から、プロセス改善に注目が集まっている感もありますが、今回の JaSST'18 Tokyoの目玉はやはりなんといっても、Google ジョン・ミッコ氏の Flaky Test だと思います。
以下では、ミッコ氏による2つのセッション
- 基調講演_A1「Advances in Continuous Integration Testing at Google」
- 基調講演者チュートリアル G5「How to identify test flakiness in your test result data テスト結果からテストの不安定性(test flakiness) を読み解く」
を取り上げて、今回参加できなかった方でも、Google社の先進的な取り組みについて概要を把握できるよう、ポイントを絞ってお伝えしたいと思います。(ブログに掲載することについては、ミッコ氏の許可を得ております。ありがとうございます!)
基調講演 セッション A1「Advances in Continuous Integration Testing at Google」、基調講演者チュートリアル G5「How to identify test flakiness in your test result data テスト結果からテストの不安定性(test flakiness) を読み解く」
講演資料 が公開されていますが、 語彙の事前知識や質疑できる場などがないとなかなか理解しにくい箇所もあると思います。 まず、趣旨(引用)とキーワードを簡単に整理した後に、セッションの要点をお伝えします。
趣旨
- より効果的なテストのスケジューリングとは
- コストの削減方法
- 不安定な自動テストへの対処(Flaky Test)
キーワード
- SETI (Software Engineer, Tools and Infrastructure)
- RTS (Regression Test Selection)
- 実行する回帰テストケース数を削減するアプローチ
- Transition
- テスト結果がPASS→FAIL または FAIL→PASSへと状態遷移すること
- Edge
- テスト結果がPASS→FAIL または FAIL→PASSへと状態遷移したチェンジリストの断片
- Greenish
- テスト成功(グリーン)のような状態
- 確信ではなく確率
- Flaky Test
- 不安定なテストのこと
- テスト結果が非決定論的
- 同じコードリビジョン、同じ入力と設定、においてテストが成功したり失敗したりする
- 不安定なテストのこと
Googleの自動テスト(概観)
- 420万の独立したテスト
- その16%は何がしかのFlakyさを持つ
- 1日あたり1億5000万のテスト実行数
- 平均して各テストが毎日に35回実行される
- 1万3000以上のチーム
- テスト実施の99%は成功する
- テスト結果がPASS→FAILに遷移したテストのうち、84%はFlaky
- テスト失敗の16%だけが欠陥を意味していた
- テストの 1.23% だけがソフトウェアの欠陥を見つけている
なんというか規模が桁違いですね!
RTSはなぜ必要か
テスト実行数を削減するため
- テスト実行の99.8%は、テスト結果の遷移を引き起こさない
- テスト結果の遷移を引き起こすような0.2%のテスト実行だけで十分なことになる
- もし完璧なアルゴリズムがあれば、すべてのテストを流し続ける必要はない
Greenishという概念がなぜ必要か
テストの量、実行回数ともに莫大で、全てを実行しきれないため
- RTSだけでは問題が多い
- マイルストーン間は、プロジェクトの状態は決定的ではない(inconclusive)
- 全テストを実行することによる「グリーンの確信」に代わり、「グリーンの確率」を提供している

図1. Greenish - 図1で、大きい緑●が「グリーンの確信」
- 図1で、モスグリーン四角が「グリーンの確率」
- チームにとってはリスクを持ってリリースすることになる
遷移を見つけるまでの時間を節約することを重視 しているようです。1日経てば「過去」であり内容を忘れている、と。
Flakyという概念がなぜ重要か
テスト結果が成功から失敗に状態遷移したときでも、その84%が誤報であるため
- システムの問題なのに、開発者にテストが不合格だったと通知がくることで調査する時間が無駄になる
- マシンリソースの 2~16%をFlaky Testのために消費している
- 全てグリーンでないとリリースしないため、リリースの妨げになる
- 無視すべきでないときもある
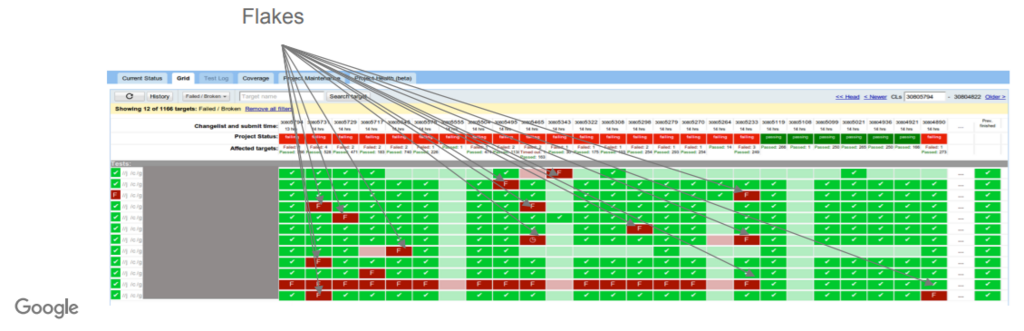
図2. Flaky - 図2で、Flakesはテスト結果が非決定論的に成功したり失敗したりするFlaky Test
Flakyなテストがあると、テスト失敗が常に欠陥を意味するとは限らなくなってしまう のです。狼少年のような存在ですね。
Flaky Testへの対処
Flaky Testを検出することで、開発者にはテスト結果に添えて「Flakyである」という旨も一緒に伝えることで、調査コストを抑える
- Flakyさは不可避(Inevitable)との見解
- Flakyさを除去するのと同程度には新たなFlakyさが埋め込まれる
Flaky なテストを単に無視したり削除するという考え方について、休憩時間にミッコ氏に直接尋ねることができました。不安定なテストはまだバグを捕まえるために価値があるので無視したり削除したりしてはならない(意訳)とのことでした。
Flaky Testの検出方法
テスト結果(PASS/FAILのバイナリ値のみ!)を残すだけで、Flaky Testへの洞察が得られるそうです。 特殊な操作は必要なく、単純なクエリで推定できるところがポイントです。
Google では テスト結果を2年間記録を残し続けている
- PASS/FAILのバイナリ値のみ
- Googleでは
*unit.xmlファイルは残していない(が残しても構わない)
テスト結果の遷移であるTransitionやEdgeに着目して、経験則を育てている

図3. Edge - 履歴を共有(同じタイミングで成功・失敗すること)する他のテストの数が多い場合はFlakyではない
- ライブラリ起因などの明確な理由がある可能性が高い
- テスト結果の遷移が多いテストは、Flakyと判断できる
- 例えば、1日に30回もテスト結果が遷移するテストがあった場合に、開発者がそれほど頻繁に直したり壊したりをしたとは到底考えられない
- 履歴を共有(同じタイミングで成功・失敗すること)する他のテストの数が多い場合はFlakyではない
チュートリアルで Flaky Test の検出を実際に Google BigQuery を使って行いましたが、とても簡単でした。
感想
自動テストへの長年の取り組みの成果として、もし自動テストを全て流せるなら「確信(100% Confident)」があるという土壌があった上で、テスト実行の運用をいかに効果的に行うか? という次元のお話でした。 確信(100% Confident)に代わる何かが必要な状況で、ビッグデータ解析を活用するところがグーグルらしいですね。 クロージングパネルでも話されていた「アメリカでは大企業、中堅企業において自動テストは既に当たり前であり、より効果的な運用についてその興味が移っている」といった言説が印象的でした。
