こんにちは、MasaKuです。
ビッグデータという言葉をよく目にしますが、その背後にある技術についてはあまり理解していませんでした。
そこで、ビッグデータを支える技術のひとつであるNoSQLについて興味が生まれたので、今回の記事では、NoSQLについて勉強した結果についてまとめようと思います。
(本記事の執筆には以下の書籍を参考にさせていただきました)
NOSQLの基礎知識
ビッグデータを活かすデータベース技術
はじめに
現在、Twitterは、1日あたり10テラバイトを超えるデータを扱っているそうです。
10テラバイトというと、書籍一冊のデータ量(50万文字)とすると書籍1000万冊分に相当します。
モバイルデバイスからも簡単にアクセスして写真や動画コンテンツを発信できるWebサービスが普及してきたことがビッグデータの発生の起因のひとつになったと言えるでしょう。
ビッグデータの対応には3Vという以下のような特徴があります。
- Volume(膨大な量)
- Velocity(速さ)
- Variery(多種多様)
今後、更にリッチな情報を扱うWebサービスが普及してくると、ビッグデータを処理する技術がますます重要になることから、NoSQLの技術発展が期待されます。
NoSQLとは
PostgreSQLやMySQLなどのRDBでは対処しづらいようなビッグデータに対応すべく生み出された技術で、SQLを使用しないということが特徴です。
「Not Only SQL」の略であり、「SQLだけでなく、新しいデータベースの技術も利用する必要があるというムーブメントのことである」と多くの方に認識されています。
しかし、「NoSQLとはズバリこういうこと!」という定義についてはまだ明確化していないようです。
NoSQLとして代表的なものには、GoogleのBigTable、アマゾンのAmazon DynamoDBなどがあります。
RDBとの違い
NoSQLとRDBとの違いについて以下にまとめました。
- 機能は豊富ではない
- データの整合性が緩い
- 結果整合性でよいという考え
NoSQLでは、RDBで当たり前に利用できるJOIN(結合)が通常はサポートされていません。
また、同時実行制御(排他制御)を成立させるトランザクションの機能が緩められており、データの整合性よりも、大量のデータを素早く処理することを優先しているという特徴があります。
NoSQLとRDBの特性の違いを説明する上で重要な「CAP定理」という定理があります。
分散型データベースシステムにおける三大要件として以下が存在します。
- Consistency(整合性)…常に同一のデータを参照する
- Availability(可用性)… 常に読み出しと書き込みができる
- Partition Tolerance(分断耐性)…ネットワークが分断されても間違った結果を引き起こさない
分散型データベースシステムでは、上記の3つのうち最大2つしか満たすことができない、というのがCAP定理です。

RDBにはACIDという特性が存在し、トランザクションが信頼性をもって実行されるための必要条件を定義されています。
一方、BASEというものも存在し「アプリケーションは常時稼働し、常に整合性を保つ必要はないが結果的に整合性がとれる状態に至るという特性を備えているべき」という考え方があります。
CAP定理の提唱者であるEricBrewer氏は以下のように説明してます。
システムに整合性(C)と分断耐性(P)が求められる場合には、AICD特性を完備しなければならない。
だが、整合性(C)よりも可用性(A)と分断耐性(P)が求められるのであれば、そのシステムはBASEの特性を持つべきである。
RDBはCA(整合性と可用性)に分類され、ほとんどのNoSQLデータベースがCP(整合性と分断耐性)かAP(可用性と分断耐性)に分類されます。
RDBとNoSQLでは期待している性能が異なることから、NoSQLがRDBを完全に代替するものではないことがわかります。
NoSQLに期待すること
NoSQL全般には以下のような要件を満たすことが期待されています。
- 一台のサーバには収容できないほど膨大なデータを扱う
- データを複数のサーバに分割して割り当てる
- 高価なハードウェア等ではなく、安価な汎用ハードウェアの上で稼働する
- データに紛失がなく、データは安全な状態に格納されている
- システム全体としては、いつでも使える状態にある
- 障害が発生しても短時間で復旧できる
- リアルタイムに近い応答性能を備えている
また、データを高速に処理する上で、高度なデータベースチューニングの技術を必要としないことも特徴です。
データのサイズや形式が頻繁に変化するようなアプリケーションをRDBでデータを高速で処理し続けるためには、データベース設計に対する高い技術力を持ったエンジニアが常時対応しなければなりません。
これまでのRDBでは十分な性能が得られなかったり、RDBで実現しようとすると、構造が複雑になり、コストがかかりすぎるという問題を回避するための手段としてNoSQLが選択肢の一つとなりうることが期待されます。
NoSQLのデータモデル
NoSQLには様々なデータモデルが存在します。
キーバリュー型
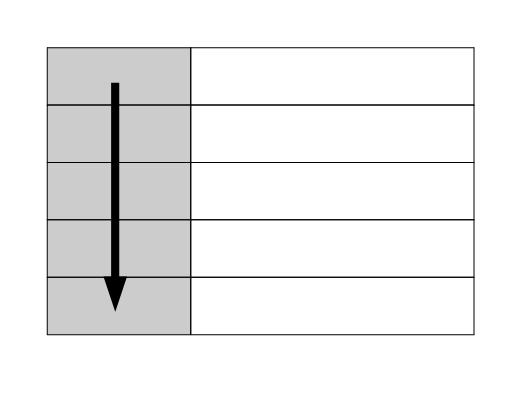
RDBのようなテーブルや関係性を定義せず、キーとバリューという組み合わせからなるシンプルなデータモデルです。
データが増えるにつれて表が縦の方向に伸びていくイメージです。
データモデルが単純であることからデータを容易に分割可能なことから、スケールアウトに最適なのが特徴です。
カラム指向型

上記のキーバリュー型にカラムの概念を持たせたデータモデルです。
行に付与されたキーが複数のカラムを持つことができます。
カラム数はRDBのように固定ではなく、動的に追加していくことができます。
RDBを利用していると異質に思えるかもしれませんが、ほかの行には存在しないカラムを持つ行を作ることができます。
ドキュメント指向型
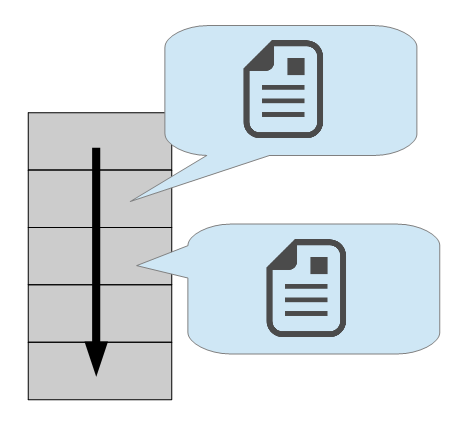
JSONやXML形式で記述されたドキュメントの形でデータを管理することができます
各ドキュメントは階層構造を持たず、相互の関係を横並びに管理します。
RDBのように固定されたデータ設計が不要なことから「スキーマレスである」と言われます。
私はドキュメント指向型の説明を読んだ際、上記のカラム指向型との違いを明確に認識することができていませんでしたが、以下のようなものなのだと理解しました。

ブログの投稿履歴とメールの送信履歴をドキュメント指向型データベースに記録したとします。
これらは全く異なる性質のデータですが「投稿日と送信日が2018/9/18のデータ」と指定することで、関係するデータが取得できます。
このようなデータの性質が異なるものや、これまで取得していたデータの形式が唐突に変わってしまうような対象でも、ドキュメントの形式でデータベースに格納し、データを処理できるようにするのがオブジェクト指向型のデータベースの特徴なのだと思いました。
グラフ型
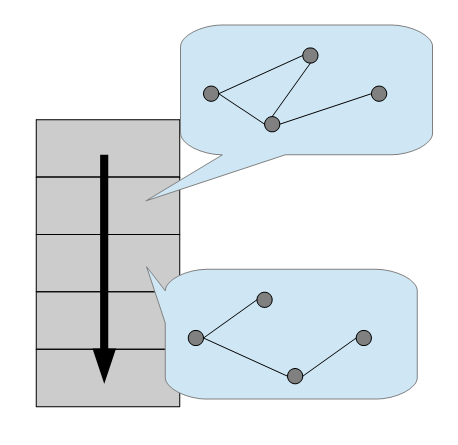
データとデータ感のつながりを管理できるデータモデルです。
グラフ型のデータベースには以下の構成で表現されます。
- ノード
- リレーションシップ
- プロパティ
例えば、FaceBookの友達関係をグラフ型で表現すると以下のようになります。
- Aさんというアカウントが存在します(ノード)
- AさんはBさんと関係があります(リレーションシップ)
- AさんとBさんは友達同士です(プロパティ)
この基本構造を拡張していくと「Aさんの友達であるBさんの友達」や「Aさんと友達になってから3年以上経過したアカウント」といった検索も可能になります。
おわりに
いかがでしたでしょうか。
筆者も、MongoDBというドキュメント指向型NoSQLを利用して簡単なWebアプリケーションを作ってみましたが、NoSQLについて調べて見ると様々なデータモデルが存在することがわかりました。
それぞれのデータモデルごとの強みが光るようなWebアプリケーションの特性についても今後調べていきたいと思いました。
参考文献
ブリュワーのCAP定理~データストレージの選定基準 - 浜村拓夫の世界
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
rakus.hubspotpagebuilder.comラクスDevelopers登録フォーム

https://career-recruit.rakus.co.jp/career_engineer/form_rakusdev/イベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください!
◆TECH PLAY
techplay.jp
◆connpass
rakus.connpass.com
