
はじめに
はじめまして。aqli_kuk120と申します。 ラクスの片隅でひっそりとインフラエンジニアをしています。
「エンジニアは常日頃の情報収集が肝要」とよく聞きますが、中々実践できない自分がいました。
技術系のニュースアプリをスマホに入れてみるも、三日坊主でついつい他の興味あることをネットサーフィンする日々…。
これではいかんと思い、対策を考えた結果、
「人気記事のリンクをスクレイピングして社内のチャットツール(Mattermost)にBOT投稿するようにしたら、昼休みにご飯食べながらみれるんじゃない?」と思い至りました。
ということで、インフラエンジニアと名乗ったものの、今回はPythonを使ったスクレイピングとMattermostへのBOT投稿についてブログを書いていきたいと思います。
スクレイピングとは
英語のscrapeには「削り取る」「こすり落とす」という意味があります。
ここでのスクレイピングは対象WebサイトのHTMLから収集した情報を削り取って、必要な情報のみを抜き出す処理のことを指します。
今回はPythonのBeautifulSoup4というライブラリを使ってスクレイピングを実行し、結果をMattermostに投稿します。
※※注意※※
前述のとおり、スクレイピングを行うとき(HTMLを取得するとき)に対象のWebサーバにアクセスが発生します。
過剰なアクセスはWebサーバに負荷をかけ、サーバをダウンさせてしまう可能性もあります。
過去に逮捕された事例もありますので、実装中の動作検証なども十分に考慮して実施するようにしましょう。
また、利用規約でスクレイピングを禁止しているWebサイトもあります。
スクレイピングをする前に対象のWebサイトの利用規約を必ず確認するようにしましょう。
Mattermostとは
オープンソースのチャットツールで、利用者が自由にチャンネルを作成することができます。
チャンネルごとにIncoming WebhookのURLを作成することができ、そのURLに適切なPOSTリクエストを送信することで外部アプリケーションから任意の投稿をMattermostに行うことができます。
Pythonで今回作るもの

開発環境構築
上図のとおりWSL2でubuntuを動かし、その中で3つのDockerコンテナを立てます。
1.Apacheコンテナ
- httpdのDockerイメージをpull、そのイメージを使ってコンテナを作成・起動します。
# ubuntu上で実行 $ docker pull httpd $ docker run -d -p 8080:80 httpd
# ubuntu上で実行 $ vi test.html <!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>TEST PAGE</title> </head> <body> <p>01のリンクをスクレイピングします</p> <a href="https://scraping-test01.html">Scraping Target 01</a> <p>02のリンクをスクレイピングします</p> <a href="https://scraping-test02.html">Scraping Target 02</a> </body> </html> $ docker ps # ApacheコンテナのCONTAINER IDを確認 $ docker cp test.html [ApacheコンテナのCONTAINER ID]:/usr/local/apache2/htdocs
2. MattermostのDockerコンテナ
- Mattermost公式ページで公開されているコマンドを使用してDockerコンテナを作成・起動します。
# ubuntu上で実行 $ docker run --name mattermost-preview -d --publish 8065:8065 mattermost/mattermost-preview
上記コマンドを実行した後、Webブラウザでhttp://localhost:8065/にアクセスすることで、Mattermostにアクセスすることができます。
→Dockerイメージをカスタマイズしたい場合、DockerfileはMattermostの公式Githubにて公開されていますので、そちらをcloneしてカスタマイズをしてください。
3. PythonをインストールしたDockerコンテナ(Webスクレイピング実行環境)
- Dockerfileを作成
# ubuntu上で実行 $ vi Dockerfile FROM centos:centos7 RUN yum install -y python3 RUN pip3 install requests BeautifulSoup4
→最低限これだけ入れておけば、とりあえず今回の「スクレイピングした結果をMattermostに投稿する」は達成できます。
その他必要なものがあれば、お好みに応じてどうぞ。
- Dockerイメージ作成・コンテナの作成・起動
# 先に作成したDockerfileと同じディレクトリで実行 docker build -t scraping . docker run --network=host -itd scraping /bin/bash
→scrapingという名前でイメージを作成して、そのイメージを指定してコンテナを作成しています。
このDockerコンテナの中からlocalhostを通って各コンテナにアクセスがしたいため、--network=hostのオプションをつけています。
MattermostでIncoming Webhookの設定
コンテナが起動していればWebブラウザでhttp://localhost:8065/にアクセスすることでMattermostにログインすることができます。
初回ログイン時にはメールアドレス、パスワード、チーム名など初期設定をする必要があるので適当に設定します。
設定後、Mattermostのメインページが表示されるので、BOT用のチャンネルを作成します。

Incoming WebhookのURLはチャンネルごとに発行することができるので、左上あたりのメニューボタンから
Integrations > Incoming Webhooksと進み、Add Incoming Webhookを選択してWebhook用のURLを発行します。

Ptyhonでスクレイピング実装
※普段はbashぐらいしか使っていないため、コードで「ん?」と思っても多めに見てください…。
コード実装はコンテナに直接ログインしてviでゴリゴリ書く、エディタでコンテナにリモートアクセスして書くなどお好みの方法でどうぞ。
私はVSCodeにRemote Developmentをインストールし、コンテナにリモートアクセスして書きました。
コンテナに直接ログインする場合は以下のコマンドを実行することでログインできます。
# ubuntu上で実施 $ docker exec -it [CONTAINER ID] /bin/bash
さて、いよいよスクレイピングの実装です。
以降のPythonのコードはすべて一つのファイルに記述していきます。
まず、スクレイピングをするために対象のHTMLページを取得する必要があります。
そのための実装が以下です。
import requests # スクレイピング対象のWebページのURLを指定 url = "http://localhost:8080/test.html" # requestsモジュールで指定したURLにGETリクエストを投げてHTMLデータを取得 # 取得したデータはres変数に格納 res = requests.get(url)
次にBeautifulSoup4を使って取得したHTMLデータのスクレイピングをします。
from bs4 import BeautifulSoup # resに格納されているHTMLの文字列データをBeautifulSoup4のHTMLパーサーで解析 # 解析結果をsoup変数に格納 soup = BeautifulSoup(res.text, 'html.parser') # find_allメソッドを使ってHTML内のaタグをすべて抽出し、article_tags変数(リスト型)に格納 article_tags = soup.find_all('a') # リストにいれたaタグの情報からhref(リンク先のURL)とテキスト(リンクのタイトル)を取得し変数に格納する article_link_list = [] article_title_list = [] for article_tag in article_tags: article_link_list.append(article_tag.get('href')) article_title_list.append(article_tag.get_text('a'))
find_all()メソッドは、Tagオブジェクトが持つ子孫要素のうち、引数に一致するすべての要素を検索します。
検索された要素はリスト型で返却されます。
この要素の検索について、BeautifulSoup4にはfind_all()以外にも、CSSセレクタを引数に検索するselect()メソッドなど、いくつか種類があります。
日本語訳されたドキュメントも検索すると見つけれますので、ぜひご確認ください。
また、このときarticle_tags、article_link_list、article_title_listにはそれぞれ以下のようにデータが格納されています。
・article_tags [<a href="https://scraping-test01.html">Scraping Target 01</a>, <a href="https://scraping-test02.html">Scraping Target 02</a>] ・article_link_list ['https://scraping-test01.html', 'https://scraping-test02.html'] ・article_title_list ['Scraping Target 01', 'Scraping Target 02']
次に、PythonでスクレイピングしたデータをMattermostに投稿します。
Mattermostへの投稿
今回は、下図のようにMattermost上で表形式になるように投稿をします。
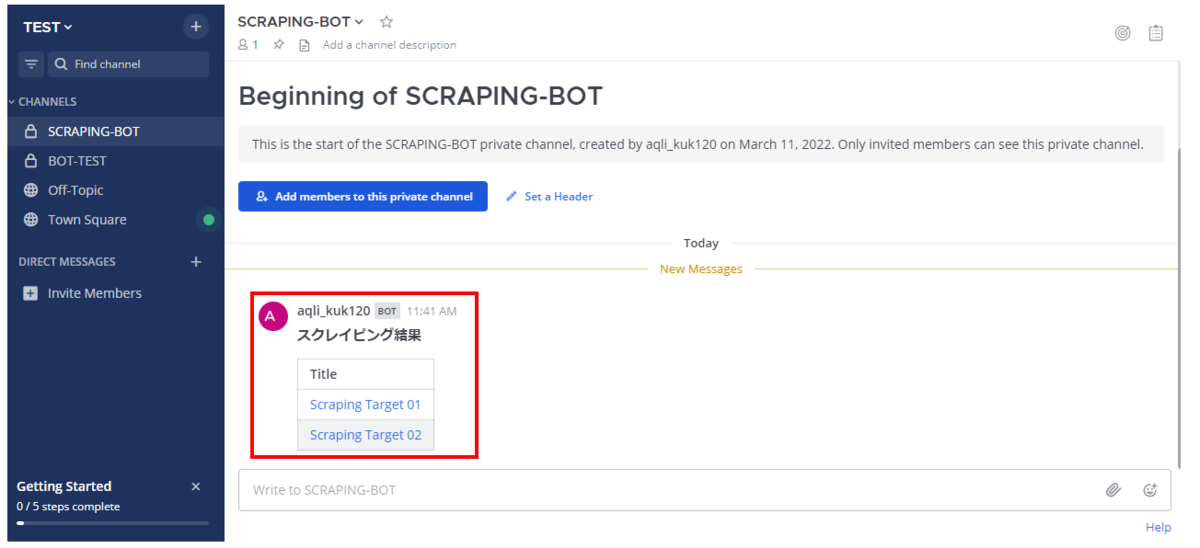
MattermostではMarkdown記法が使えるので、スクレイピングした結果をそのように加工して一時ファイルに出力します。
# スクレイピング結果を一時ファイルに出力 with open('post_to_mattermost.txt', 'w') as f: # 表の見出しを1行目に記載 f.write("##### スクレイピング結果\n|Title|\n|:--|:--|\n") # スクレイピング結果を格納したリストの内容をすべてファイルに出力する i = 0 for i in range(len(article_title_list)): article = "|" + "[" + article_title_list[i] + "]" + "(" + article_link_list[i] + ")" + "|" f.writelines(article + "\n")
Incoming Webhookを使ってMattermostに投稿する場合は、JSON形式でリクエストを投げる必要があります。
そのため、先ほど作成した一時ファイルを読み込み、JSON形式に変換して変数に格納します。
post_data={}
with open('post_to_mattermost.txt', 'r') as f:
post_data.update({'text':f.read()})
Pythonの辞書型はJSONとして利用することができるので、keyにtextを格納し、valueに一時ファイルの内容を格納します。
keyをtextにしているのは、投稿本文のkeyはtextにするというルールがあるためです。
そのあたりの細かいルールについてはMattermostの公式ドキュメントをご確認ください。
最後に作成したIncoming WebhookのURLに対して、POSTリクエストを送信する処理を実装して完成です!
webhook_url = "[Incoming WebhookのURL]" headers = {'Content-Type': 'application/json',} json_post_data = json.dumps(post_data, ensure_ascii=False).encode('utf-8') requests.post(webhook_url, headers=headers, data=json_post_data)
最後に
今回はブログ用にスクレイピング対象のHTMLはかなり簡略化したものを使いましたが、
「必要な要素を取得する」が基本(だと思っている)ので、HTMLが複雑であってもやることはそんなに変わらないと思います。
日頃、Pythonでのプログラミングや、こういったブログも書く機会がないので、未熟な点が多々あったと思いますが、なにかの手助けになれば幸いです。
最後までお読みいただきありがとうございました!
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
rakus.hubspotpagebuilder.comラクスDevelopers登録フォーム

https://career-recruit.rakus.co.jp/career_engineer/form_rakusdev/イベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください!
◆TECH PLAY
techplay.jp
◆connpass
rakus.connpass.com
