
はじめに
みなさんこんにちはインフラエンジニアのa_renrenです。
日々、サーバを運用される方であれば、サーバの不具合や高負荷などで引き起こされるアラートの対応しているかと思います。
その対応手順は手順書としてまとまっていることが少なく、今までの経験則に基づいて対応を行ったり、ベテランメンバーに頼ったりしているところも少なくないかと思います。
自分のチームも各々で手順やノウハウをまとめたりしていますが、共通の手順がほぼない状況でした。そのような現状を打開するため、アラートの対応手順を作成したので、今回はその時の振り返りをしようかと思います。
文字ばかりになってしまい、読みにくいかと思いますがご容赦ください。
※ 障害が発生した際は別途対応フローや手順がありますので、対象外としています
※ 一部、実際の運用方法と変えて記載したりしていますので、ご了承ください
アラートの対応方法
まずは、自分のチームでどういう感じでアラートを対応しているか軽くご紹介します。
自分が所属するチームでは2つの商材を担当しており、その2つの商材のアラートの対応をおこなっています。
各サービスごとサーバ監視システム(Zabbix)を使用してサーバの運用管理を行っており、そのシステムからのアラートをトリガーに対応を開始しています。
もし、アラート対応方法がわからない、判断できない場合は、チーム内で確認し、詳しいメンバーに判断仰ぎながら対応を行っています。
なぜ取り組んだのか
この取り組みをする前は以下のような課題がありました。
新しいメンバーがアラートの対応を行いにくい
人によってアラートの対応方法に差がある
アラート対応のノウハウがあまり共有できていない
一部のアラートの対応が属人化している
チーム外の人がアラートの対応を行いにくい
経験が浅いとすぐに対応が必要なものとそうでないものの判断が難しい
これらの課題を克服するために、アラートの対応手順を今回作成しました。
目的をまとめると以下のような感じです。
アラートの対応方法を統一化し、対応する人によるばらつきをなくす
各メンバーが持っているアラートの対応手順を共有できる場をつくる
新しいメンバーやチーム外のメンバーでもアラートの1次対応がスムーズに行えるようにする
ターゲットを新しいメンバーやチーム外などのあまり商材の知識がない人にし、なるべく判断に迷わない具体的な手順を意識して作成を行いました。
また、対応手順と言っても時と場合によって対応方法が変わるため、最低でもこの手順を見れば1次対応が行えるようにしました。
作成はある程度、自分の経験などをもとにたたき台をつくり、情報が足りなければ詳しい人に確認しつつ作成を行いました。
作成したすべてのアラートの対応手順をチーム内でレビュー会を開いて意見を募り、最終的な形にしていきました。
作成したもの
今回、アラート対応手順は、Markdown形式で作成し、それを社内のGitLabにあげて管理するようにしました。
Markdownにしたのは、シンプルに作成でき、ある程度雛形を作成しておけば、今後他のメンバーが作成する際も
あまり負担がないかと思ったからです。
GitLabで管理したのは、変更の差分が管理しやすく、Markdown形式で表示されて見やすいからです。
今回作成したフォーマットは以下のような感じです。
実際のアラート対応手順はお見せできないので、フォーマットとサンプル情報でお許しください。。。
()内のは説明で実際には記載していません。
アラートの大まかな分類以外は目次にならないようにMarkdown上で別途設定しています。
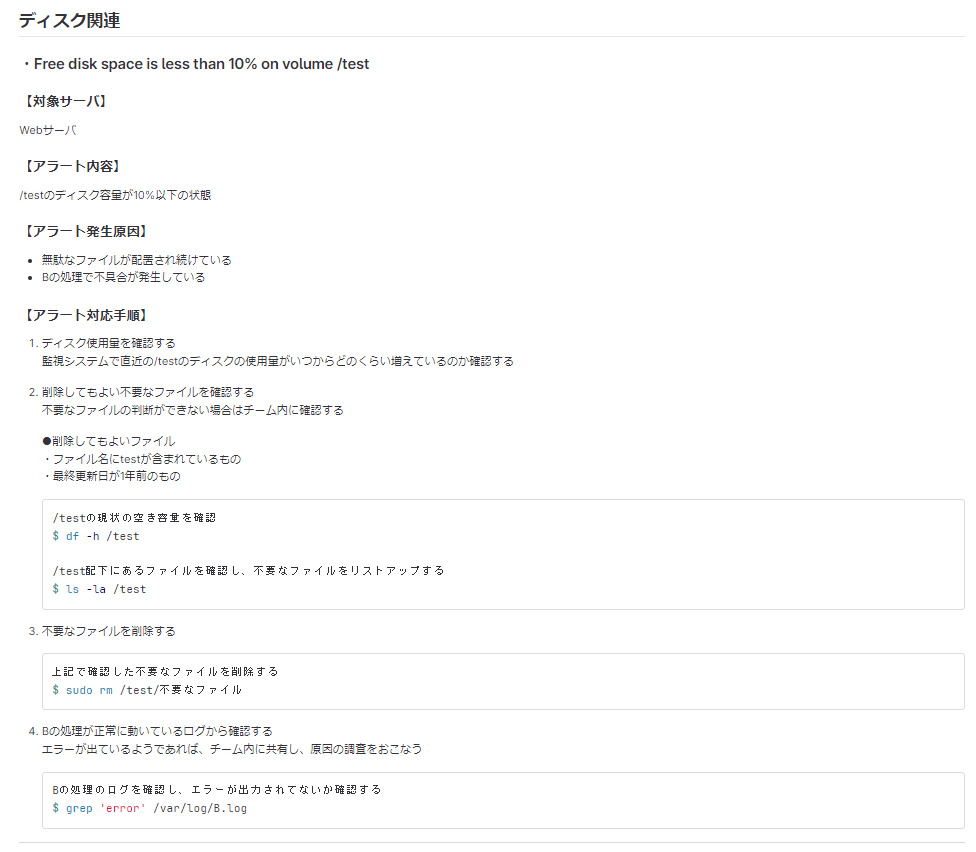
## ディスク関連 (アラートの大まかな分類 ディスク関連のアラートはこの分類の中にまとめる) ### ・Free disk space is less than 10% on volume /test (通知されるアラートのタイトル) #### 【対象サーバ】 Webサーバ #### 【アラート内容】 /testのディスク容量が10%以下の状態 (アラートの発報条件やアラートが発報されることでどういう状態なのかを記載) #### 【アラート発生原因】 - 無駄なファイルが配置され続けている - Bの処理で不具合が発生している (考えられる原因を記載) (調査の際にここに記載した考えられる原因から調査が行いやすいようにする) #### 【アラート対応手順】 (アラートの対応手順を記載) 1. ディスク使用量を確認する 監視システムで直近の/testのディスクの使用量がいつからどのくらい増えているのか確認する 1. 削除してもよい不要なファイルを確認する 不要なファイルの判断ができない場合はチーム内に確認する ●削除してもよいファイル ・ファイル名にtestが含まれているもの ・最終更新日が1年前のもの ```bash /testの現状の空き容量を確認 $ df -h /test /test配下にあるファイルを確認し、不要なファイルをリストアップする $ ls -la /test ``` 1. 不要なファイルを削除する ```bash 上記で確認した不要なファイルを削除する $ sudo rm /test/不要なファイル ``` 1. Bの処理が正常に動いているログから確認する エラーが出ているようであれば、チーム内に共有し、原因の調査をおこなう ```bash Bの処理のログを確認し、エラーが出力されてないか確認する $ grep 'error' /var/log/B.log ```
GitLab上では、以下のように表示されます。
アラート対応手順を作成してみて
今回アラートの対応手順を作成してから、まだ月日は経っていないため、あまり活躍はできてなさそうですが、 以前よりアラート対応方法が統一になったり、ノウハウの共有が行いやすくなったり、 新メンバーへのレクチャーも行いやすくなったかと思います。
上記以外にも、アラートの対応手順を作成していく過程でメリットがありました。
一つ目は、不要なアラートを洗い出し、削除することが出来たことです。
アラートの対応手順を作成していく中で、いろいろなアラートが見つかりました。。。
- 何のためのアラートなのかわからないアラート
- 今はもう不要になったが、削除されず残り続けているアラート
- 同じようなことを監視しているアラートなど
上記のように必要なアラート以外に様々なアラートが見つかりました。その見直しをこの機会に行えたことで、不要なアラートを削減することができ、不必要な対応する負担が減りました。また、より良い監視方法が見つかったりと、あまり注目されてこなかった箇所にメスを入れることができました。
二つ目は、アラートがならないよう仕組みづくりの見直しをおこうことができたことです。
アラートの予測される発生原因を探っていく中で現状の設定値がベストでないことに気づき、設定値の改善をおこなったり、
ある条件で失敗する可能性があるスクリプトの処理を失敗しないようにスクリプトの実装方法を変えるなどの見直しを行うことができました。
また、作成していくなかで対応しきれなかった課題もありました。
似たようなアラートの対応手順を一つにまとめきれず、アラートごとに一部似たような対応手順をそれぞれに記載したため、メンテナンス性が悪い状態になりました。
似たような手順を外出ししようかとも思ったのですが、対応するメンバーがいろんなファイルを行ったり来たりすると対応しにくいかと思い、あえて外出しはしませんでした。
今後、対応できるサーバを増えるにつれ、アラートの種類も増え、よりメンテナンス性が悪くなりそうなので、早めに作成者と対応者のどちらの負担も軽減できるように構成を変えていく必要がありそうです。
今後について
今回は、一部のサーバのアラート対応手順しか作成できなかったため、今後も上記の課題を解決しつつ、引き続き残りのサーバのアラート対応手順を作成をチームで進めていこうかと思います。
また、並行してアラートの削減やアラート対応の自動化などの根本的な対応も進めていければと思っています。
皆さんもこの機会にぜひアラートの見直しや対応手順の作成に取り組んでみてはいかがでしょうか。
最後までお読みいただきありがとうございました。
