 皆様こんにちは。インフラエンジニアのryuhei55225です!
皆様こんにちは。インフラエンジニアのryuhei55225です!
前回の記事は【Kibana 入門】という形で「Elastic Stack」(Kibana+Logstash+Elasticsearch)をLinuxサーバにインストールして、簡単なデータのグラフ化を紹介させて頂きました。
こちらの記事では、MWのインストール等のサーバ構築がメインとなってしまい、具体的なElasticsearchへのデータ投入やデータ検索・グラフ化に関しては紹介することが出来ておりませんでした。
(データ検索・グラフ化に関しては、完全に省略しておりました。。)
ということで・・・
今回の記事は「Kibana 基礎」という形で、実際前回構築したサーバのElasticsearchにLogstash経由でデータを投入して、Kibanaにてデータをグラフ化をしていく流れについて、具体的に紹介していこうと思います。
今回の流れとしては、
- まず、Logstashの機能について一般的なことを紹介
- その後、実際に今回やってみた内容(データのグラフ化)を紹介
していきます。
なんで、Logstashについてある程度理解されている方は、「実際にやってみた」から見て頂ければと思います。
Logstashを用いたデータの収集・加工・転送
Logstashは、さまざまなデータソースからのログやデータを、収集・加工・転送するためのツールです。
前回の記事では、その中の機能の一部として、CSVファイルからデータを収集して、Elasticsearchにデータを転送する形を紹介させて頂きましたが、実際にLogstashで出来ることはたくさんありますので、もう少しその要素(コンポーネント)について見ていきたいと思います。
Logstashの設定は、大きく「Input」「Filter」「Output」に分けられます。
「Input」でデータを収集して、「Filter」で加工、「Output」で転送という流れです。
それぞれのプラグインごとに、様々なものと連携可能ですので、ざっくりプラグインについて紹介していこうと思います。
Inputプラグイン
Inputプラグインで対応しているデータの取得対象は数多くあります。
全て紹介することは出来ませんので、今回は前回しようした「file」をもう少し詳細に紹介していこうと思います。
その他にも、「Elasticsearch」を指定することで、Elasticsearchのデータを取得するなんてことも出来ます。
以下サイトに対応しているプラグインの記載がありますので、詳しくはやりたいことにあったプラグインを調べてもらえればと思います。
www.elastic.co
Filterプラグイン
Filterプラグインでは、実際にデータの整形を実施していきます。
こちらも様々なプラグインが存在しますが、今回は実際にInputプラグインで指定したCSVファイルを整形するにあたって、よく使うプラグインや便利なプラグインについて紹介していきます。
こちらも、以下サイトに対応しているプラグインの記載がありますので、もっと勉強したい方はこちらも参考にして頂ければと思います。
www.elastic.co
Outputプラグイン
最後にOutputプラグインです。
こちらはデータの出力先となり、様々なプラグインに対応がありますが、「Elastic Stack」を構成している場合は、ほとんどElasticsearchになるかと思います。
今回も実際にCSVファイルからInputしたデータを、Filterで整形して、ElasticsearchにOutputする形を紹介していきます。
www.elastic.co
実際にやってみた
ということで、早速サンプルデータをLogstash経由でElasticsearchに投入して、Kibanaでグラフ化していく流れを紹介していきます。
データの準備
今回用意したデータは、以下のようにtest-serv01~50のサーバのディスク容量を使用量を残容量に分けて一週間に一度計測したデータをCSVファイルにしています。
こちらのデータをElasticsearchに投入していこうと思います。
# cat /data/server_disk_check.csv 2021/10/01 00:00:00,test-serv01,DBディスク使用量(GB),51.890850067139 2021/10/01 00:00:00,test-serv01,残DBディスク容量(GB),55.363399505615 2021/10/01 00:00:00,test-serv02,DBディスク使用量(GB),38.047119140625 2021/10/01 00:00:00,test-serv02,残DBディスク容量(GB),49.211036682129 2021/10/01 00:00:00,test-serv03,DBディスク使用量(GB),40.542625427246 2021/10/01 00:00:00,test-serv03,残DBディスク容量(GB),46.715530395508 2021/10/01 00:00:00,test-serv04,DBディスク使用量(GB),37.850318908691 ・ ・ ・ 2021/10/01 00:00:00,test-serv49,DBディスク使用量(GB),24.080196380615 2021/10/01 00:00:00,test-serv49,残DBディスク容量(GB),103.170146942139 2021/10/01 00:00:00,test-serv50,DBディスク使用量(GB),3.631404876709 2021/10/01 00:00:00,test-serv50,残DBディスク容量(GB),83.626750946045 2021/10/08 00:00:00,test-serv01,DBディスク使用量(GB),51.983116149902 2021/10/08 00:00:00,test-serv01,残DBディスク容量(GB),55.271133422852 2021/10/08 00:00:00,test-serv02,DBディスク使用量(GB),38.138965606689 2021/10/08 00:00:00,test-serv02,残DBディスク容量(GB),49.119190216064 ・ ・ ・ 2022/05/27 00:00:00,test-serv49,DBディスク使用量(GB),26.486736297607 2022/05/27 00:00:00,test-serv49,残DBディスク容量(GB),100.763607025146 2022/05/27 00:00:00,test-serv50,DBディスク使用量(GB),13.513370513916 2022/05/27 00:00:00,test-serv50,残DBディスク容量(GB),73.745048522949
Logstash設定ファイルの作成
このデータをElasticsearchに投入するための設定ファイルを以下のように記載します。
これで、CSVファイルのデータをそのままElasticsearchに投入可能です。
# cat /etc/logstash/conf.d/server_disk_check.conf
input {
file {
path => "/data/server_disk_check.csv"
start_position => "beginning"
type => "server_disk_check"
}
}
filter {
if [type] == "server_disk_check" {
csv {
columns => [
"date"
, "host"
, "item"
, "number"
]
separator => ","
}
date {
match => [
"date"
, "YYYY/MM/dd HH:mm:ss"
]
}
mutate {
convert => {
"number" => "float"
}
}
}
}
output {
if [type] == "server_disk_check" {
elasticsearch {
hosts => ["localhost:9200"]
index => "%{type}"
}
}
}
設定の反映と確認
上記ファイルを作成したら、Logstashのサービスを再起動して、Elasticsearchにインデックスが作成されていることを確認します。
# systemctl start logstash.service # curl -XGET 'http://localhost:9200/_cat/indices?' yellow open server_disk_check wKGD-LlKSPqZjHJK8UMa_Q 1 1 3500 0 730.9kb 730.9kb
curlでElasticsearchの情報をとってきて、「server_disk_check」のインデックスが作成されていることを確認できれば、一旦OKです。
※ここでElasticsearchにインデックスが作成されていない場合は、「/var/log/logstash/logstash-plain.log」を確認しましょう。
設定ファイルの書式間違い等であれば、こちらのログに何が間違えているか記載されていることが多いです。
今回作成した設定ファイルについて
では、設定ファイル(/etc/logstash/conf.d/server_disk_check.conf)に話を戻して、詳しく設定内容について確認していきます。
Inputプラグイン
まずInputからですが、今回はCSVファイルからのデータ取得ですので、fileプラグインを使用します。
「path」
- ここで、読み取るCSVファイルのパスを指定します。
当たり前ですが、ここで設定しないと、Logstashはどのファイルを読み取ればいいのか、判断つきません。
- ここで、読み取るCSVファイルのパスを指定します。
「start_position」
- こちらは、Logstash起動時にファイルの行頭から読むのか末尾から読むのかを指定します。
今回のデータに関しては、タイムスタンプ(date)も同時に出力するので、どちらでも問題はないのですが、通常ファイルの最初からデータを作成するので、作成した順にデータの読み取るよう、「beginning」を指定します。
※デフォルトは、「end」(末尾から読み取り)になっているようです。
- こちらは、Logstash起動時にファイルの行頭から読むのか末尾から読むのかを指定します。
「type」
- Logstashで取得するデータが今回のものだけであれば、こちらの設定は不要になりますが、明示的に「type」を設定することで他のLogstashの設定と混ざらないようにします。
ここでは、分かりやすいように、ファイル名=インデックス名=「type」=「server_disk_check」とします。
※もちろん、それぞれの名前を分けることも可能です。
- Logstashで取得するデータが今回のものだけであれば、こちらの設定は不要になりますが、明示的に「type」を設定することで他のLogstashの設定と混ざらないようにします。
Filterプラグイン
続いてfilterについて確認していきます。
流れ的にはInputしたCSVファイルからデータを取得して意図した形にデータを整形することになりますが、その前にInputで使用した「type」(server_disk_check)の条件分岐をしてあげます。
※これを忘れると、他のインデックスに影響を与えてしまします。
「csv」
「date」
- Elasticsearch で「timestamp」として使用するカラムの日時フォーマットを指定します。
CSVファイルに記載したフォーマットをそのまま記載すればOKです。
- Elasticsearch で「timestamp」として使用するカラムの日時フォーマットを指定します。
「mutate」
- CSVファイルから取得したデータは、デフォルトで文字列として認識されて、Elasticsearchに出力されてしまいます。
そのため、数値については、convertを使用してfloat等にデータ型を変更する必要があります。
mutateについては、convert以外にも使用可能ですが、今回は省略させて頂きます。
- CSVファイルから取得したデータは、デフォルトで文字列として認識されて、Elasticsearchに出力されてしまいます。
Outputプラグイン
最後にoutputです。ここは特に難しいことはしておらず、見たままかと思います。
今回は、「type」=インデックス名としたので、インデックスの指定を"%{type}"としています。
Kibanaを用いたGUIでのElasticsearchデータ確認
続いて、Elasticsearchに入れたデータを実際にKibanaで確認してグラフ化していきたいと思いますのが、 その前に、Elasticsearchにどのような形でデータが投入されているかKibanaのGUI上で確認していこうと思います。
まずは、Kibanaに新しく作成したインデックスをElasticsearchに登録します。
メニューから、「Stack Management」→「Index patterns」と選択して、「Create index pattern」からインデックスをElasticsearchに登録していきます。

※次の画面で出てくる「Time field」に関しては、「date」を選択してあげます。
インデックスの登録が完了しましたら、実際にどのような形でElasticsearchにデータが投入されているか確認していきます。
今回はKibanaのDiscover画面から確認していきます。
続いての画面で、
①:今回作成したインデックスを選択
②:対象期間を選択(今回は一年)
③:表示するカラムを選択※デフォルトだと全て表示されるため、見づらくなります
を実施していくと、以下のような形で、実際にElasticsearchにデータが投入されていることが確認できます。

この時点でKibanaのFilterを駆使することで、見たいデータだけを選択することも可能ですが、
今回は「Visualize Library」からElasticsearchのデータをグラフ化する流れについて説明していきます。
KibanaによるElasticsearchデータのグラフ化
ようやくElasticsearchにデータが投入されていることが確認できましたので、ここから実際にグラフ化していきたいと思います。
グラフの選択
グラフ化に関しては、「Visualize Library」という部分から実施していきます。

上記、画面で「Create visualization」を選択して、作成するグラフを選択していきます。 今回は、単純にディスク容量の推移を確認するために、折れ線グラフを使用していきたいと思います。 以下のように、選択して最後に対象インデックスに今回作成したものを選択します。
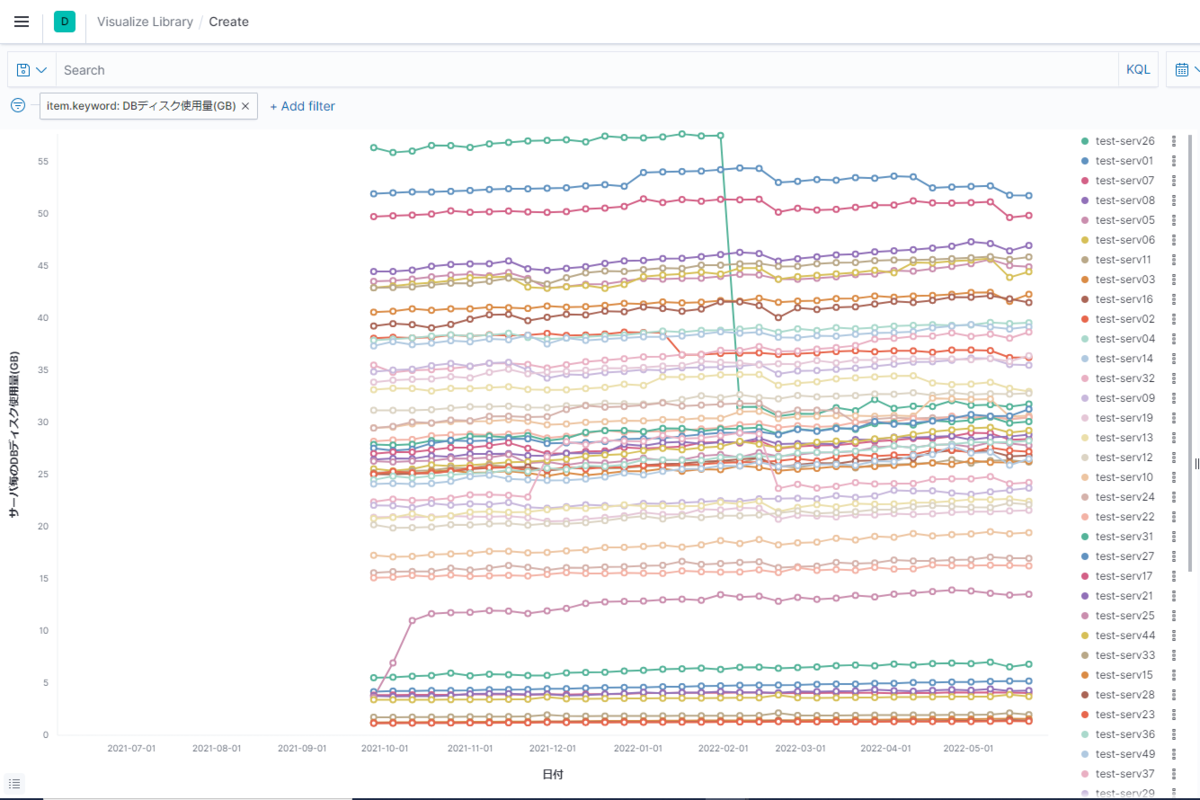
続いて、GUI上からグラフの設定をしていくことで、以下のようなグラフを作成していきます。
今回は、サーバ毎のディスク使用量の推移をグラフ化していきます。
(あくまで参考ですので、自身で実施する際はこちらを参考に、色々設定をいじってみてください。)
では、続いてグラフ作成の手順を紹介していきます。
対象のデータを選択
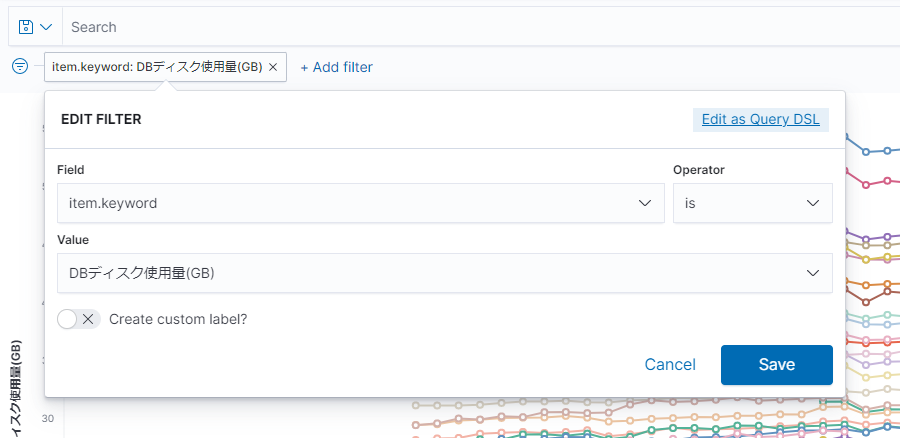
今回Elasticsearchには、「DBディスク使用量(GB)」と「残DBディスク容量(GB)」の2種類が存在しますので、
「DBディスク使用量(GB)」のみが対象になるように、フィルターしてあげます。
フィルターは画面左上の「Add filter」から以下のように設定してあげます。
Y軸の設定
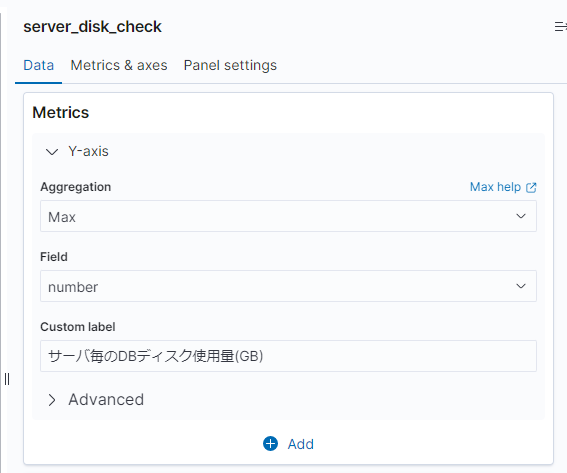
画面右に表示されている設定の「data」から「Metrics」の設定をしていきます。
具体的に言うと、Y軸に何の値をとるか、です。
Aggregation
- 今回は、サーバ毎にデータが一つしかありませんので、設定はなんでも問題ありません。
もし、全サーバのディスク容量の合計を表示したいとかであれば、こちらを「Sum」にする必要があります。
※その場合は、グラフの分割方法についても修正する必要があります。
- 今回は、サーバ毎にデータが一つしかありませんので、設定はなんでも問題ありません。
Feild
- 今回は、実際の値(ディスク容量)を表示したいので、Elasticsearch内のカラム「number」を「Field」に選択します。
Custom label
- グラフのラベル(Y軸)に何を書くかです。
設定しなくてもグラフ化は可能ですが、設定しておくとグラフが見やすくなります。
- グラフのラベル(Y軸)に何を書くかです。
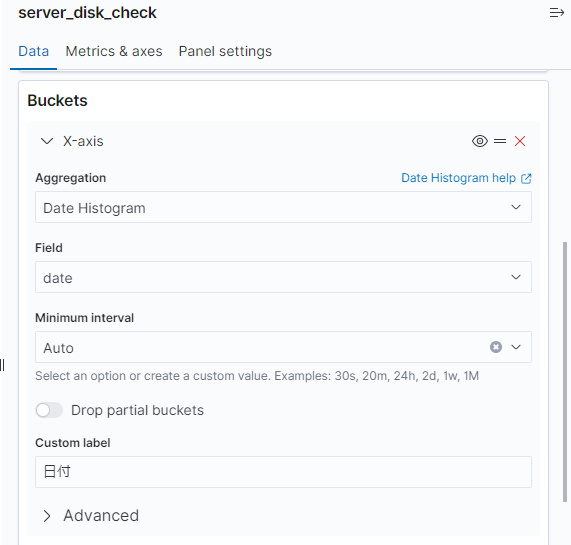
X軸の設定
続いて、「Buckets」でX軸の設定をしていきます。
今回は、時系列のグラフを作成するので、X軸に日付を選択していきます。
具体的には、「X-axis」を以下のように設定します。
続いて、「Split series」でグラフの分割方法を選択していきます。
今回はサーバ毎に折れ線を分けたいと思いますので、「Sub aggregation」で「Terms」を選択して、
「Field」で分割する単位である「host.keyword」を選択します。

これで、グラフの設定は以上です。
ここまで設定すれば、初めに見せたグラフが表示されるはずです。
最後に
今回はグラフ化ということで紹介はここまでにさせて頂きますが、Kibanaでは様々なグラフが作成できますので、実際に触っていくと、「こんなこともできるのか」といった発見があるかと思います!!
サーバ毎の推移をグラフ化しましたが、その他にもディスク使用容量の全体の合計値の推移や、単位時間当たりのディスク使用容量の最大値の取得等、データさえ入っていれば、だいたいのことは出来ると覆います。
一般的な監視ツール(Nagios、Zabbix、etc...)でも簡単なグラフの作成は可能ですが、Kibanaに比べると対応しているグラフは少ないかと思います。
そんな時は一度Kibanaにデータを移行してあげれば、作成したグラフが簡単に取得できる、なんてこともあるかと思います。
ということで、今回の紹介は以上にさせて頂きたいと思います。
次回も書くことがあれば、「応用編」としてElasticsearchやLogstashの便利な使い方について紹介していこうと思います。
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
rakus.hubspotpagebuilder.comラクスDevelopers登録フォーム

https://career-recruit.rakus.co.jp/career_engineer/form_rakusdev/イベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください!
◆TECH PLAY
techplay.jp
◆connpass
rakus.connpass.com
