
はじめに
ラクスのサービスでは請求書や領収書をはじめ、様々な文書を取り扱っています。
例えば楽楽精算では領収書の読み取り機能を有しており、この機能にはAIを用いた画像認識を活用しています。
このように文書画像を対象としたAI(以下、本記事では文書画像読解AIと呼びます)は、様々なタスクに応用できます。
そこで今回の記事では、文書画像読解AIではどのようなタスクを解くことができるか、代表的なものを紹介します。
また各タスクに適用できるモデルについて、本記事執筆時点でのSOTAモデル*1をいくつか簡単に紹介します。
文書画像を扱うタスクやモデルにどのようなものがあるか、概要を知りたい方に向けた内容となっております。
目次
サマリー
- AIで解くことができる文書画像タスクには様々なものがある。特にOCRは別タスクの前処理としても扱われることがあり、重要な基礎技術である。
- 一つのアルゴリズムで複数のタスクに応用できるモデルがある。
- 画像とテキスト両方の特徴を活用したマルチモーダルAIが、各タスクで高い精度を発揮している。
文書画像読解AIのタスク
上述のように、文書画像読解AIは様々なタスクに活用できます。 本章ではそのうち5つのタスクを紹介します。 各タスクではAIの入出力のフォーマットが異なるのが特徴です。
OCR(Optical Character Recognition、光学文字認識)
画像データに含まれる文字(活字、手書き)を、PCが処理可能な文字データに変換するタスクです。 AIに画像を入力すると、以下のように文字の内容と座標(検出枠)が出力されます。

OCRは主に「検出」と「認識」の2段階の処理に分解できます。 (※検出と認識を組み合わせたような Text Spotting というタスク・手法もありますが、本記事では扱いません。)
検出では文書画像中に含まれた文字の位置を推測し、認識では検出した文字が何であるかを推測します。
OCRは後述の別タスク「情報抽出」などの前処理として採用されることもあり、文書画像読解AIの基礎技術と言うことができます。
レイアウト解析 (Document Layout Analysis)
文書画像に含まれる文章、表、タイトル、図などを検出(またはセグメンテーション処理)するタスクです。
検出の場合、AIの入力値は画像、出力値は座標と分類クラスとなります。
以下は論文画像をレイアウト解析した例で、青が図(figure)、緑が文章(text)、黄色が表(table)、赤がタイトル(title)となっています。

文書画像分類 (Document Image Classification)
画像の特徴から文書が何の種類か判定するタスクです。例えば請求書、領収書、納品書などへ分類します。
AIの入力は画像、出力は分類したクラスとなります。
情報抽出 (Key Information Extraction)
文書画像に含まれる特定の項目を推論します。例えば請求書に記載された日付、会社名、請求金額などを推測します。
手法によりますがAIの入力は画像と文字情報(座標と文字の内容)、出力は項目名と値のペア(Key-value pair)となることが一般的です。
例えば以下の例では、レシート画像(a)を入力すると(b)のようにAIから出力されます。(c)は正解値であり、この例ではAIが正確に推論できていることがわかります。

DocVQA (Document Visual Question Answering)
正確にはDocVQAというのはデータセットの名前で、文書の内容に関する質問を投げると、画像に含まれた情報から回答を出力するタスクです。
AIの入力は文書画像と質問内容となります。
以下はその一例で、”Q”が質問内容、”Answer”が正解値、”Donut”と”LayoutLMv2-Large-QG”がAIの出力です。

文書画像読解AIのSOTAモデル
本章では、前章の5つのタスクについてSOTAモデルについて簡単に紹介します。
SOTAを紹介する上での補足事項です。
- 全て紹介すると長くなってしまうので、今回は上位5個程度抜粋しました。同じアルゴリズムでパラメータ設定などが異なるものについては、最良のモデルのみとしています。
- 今回紹介するSOTAモデルの結果には”Papers With Code” [4]というサイトや各モデルの論文を活用しております。紹介する内容は本記事執筆時点での情報である点はご了承ください。
- 各タスクによってデータセットや評価指標が異なりますが、それらについての詳細解説は省略させていただきます。
OCR
OCRは検出と認識に分割できると述べました。
したがって本記事では検出: Scene Text Detectionのモデル、認識: Scene Text Recognition のモデルとしてそれぞれ個別に紹介させていただきます。
※ Tesseract や PaddleOCR などのOCRエンジンについては本記事では触れておりません。
Scene Text Detection
評価データ Total-Textを使用した場合です。 評価指標はF値を用いています。[5]
| モデル | F値(%) | 報告年 |
|---|---|---|
| MixNet | 90.5 | 2023 |
| SRFormer | 90.0 | 2023 |
| DPText-DETR | 89.0 | 2022 |
| FAST-B-800 | 87.5 | 2021 |
| TextFuseNet | 87.5 | 2020 |
Scene Text Recognition
評価データ ICDAR2015の場合です。 評価指標はAccuracy(正解率)を用いています。[6]
| モデル | 正解率 | 報告時期 |
|---|---|---|
| CLIP4STR | 90.6 | 2023 |
| PARSeq | 89.6±0.3 | 2022 |
| S-GTR | 87.3 | 2021 |
| MATRN | 86.6 | 2021 |
| CDistNet | 86.25 | 2021 |
レイアウト解析
PubLayNet val というデータセットを用いた評価です。 評価指標はmAP@IoU[0.50:0.95]を使用しています。[7]
| モデル | mAP@IoU[0.50:0.95] | 報告時期 |
|---|---|---|
| LayoutLMv3 | 0.951 | 2022 |
| DiT-L | 0.949 | 2022 |
| Deit-B | 0.932 | 2020 |
| BEiT-B | 0.931 | 2021 |
文書画像分類
RVL-CDIPという16種類の文書画像が含まれたデータセットを使っています。 評価指標はAccuracy(正解率)を用いています。[8]
| モデル | 正解率 | 報告時期 |
|---|---|---|
| DocFormerBASE | 96.17 | 2021 |
| LayoutLMv3 Large | 95.93 | 2022 |
| LiLT[EN-R] BASE | 95.68 | 2022 |
| LayoutLMv2 Large | 95.64 | 2020 |
| TILT Large | 95.52 | 2021 |
| Donut | 95.3 | 2021 |
情報抽出
CORDというデータセットを使った評価です。 評価指標はF値となります。[9]
| モデル | F値(%) | 報告年 |
|---|---|---|
| GeoLayoutLM | 97.97 | 2023 |
| LayoutLMv3 Large | 97.46 | 2022 |
| DocFormer Large | 96.99 | 2021 |
| LiLT | 96.07 | 2022 |
| LayoutLMv2Large | 96.01 | 2020 |
DocVQA
DocVQAというデータセットでの評価結果です。 評価指標はANLS(Average Normalized Levenshtein Similarity)となります。[10]
| モデル | ANLS | 報告年 |
|---|---|---|
| ERNIE-Layout Large | 0.8841 | 2022 |
| TILT Large | 0.8705 | 2021 |
| LayoutLMv2 | 0.867 | 2020 |
| LayoutLMv3 Large | 0.8337 | 2021 |
モデルの一例
ここでは上述のモデルのうち、複数のタスクで使用できる「LayoutLM」と「Donut」をピックアップして簡単に紹介します。
これらのモデルは学習に使うデータ形式を変えることで、複数のタスクに対応できるように開発されています。
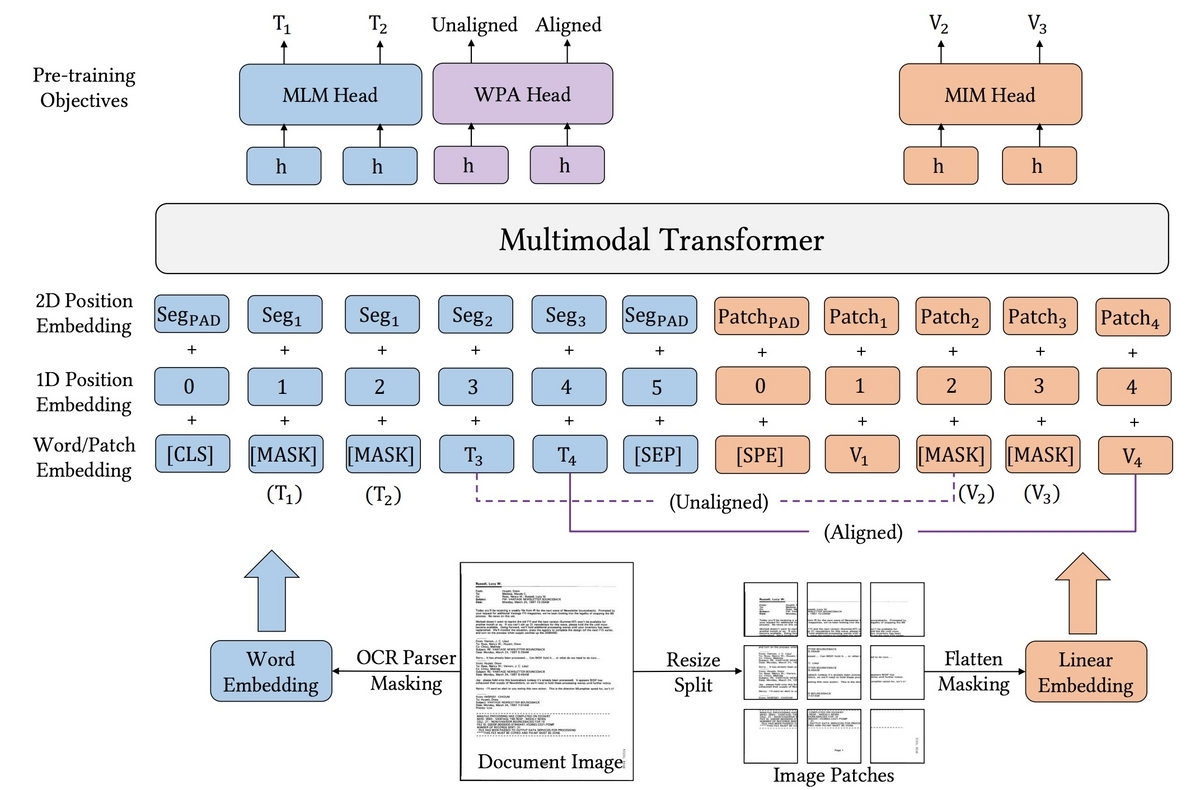
LayoutLM
適用可能タスク: レイアウト解析、文書画像分類、情報抽出、DocVQA
OCRによる文字情報と、画像の特徴を両方学習させるマルチモーダルモデルです。 これまでにv1〜v3が開発されています。
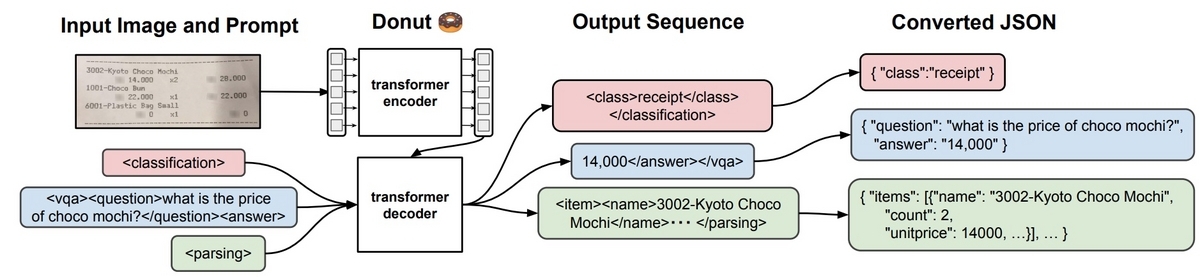
Donut (OCR-free Document Understanding Transformer)
適用可能タスク: 文書画像分類、情報抽出、DocVQA
画像とプロンプトを与えると結果を出力します。 OCR処理を使わないのが特徴です。
終わりに
本記事では文書画像読解AIについて、AIが扱えるタスクとそのモデルについて簡単に紹介しました。 新しいモデルが次々に開発される分野ですので、今後も注目していきたいと思います。
また現在ラクスではAIエンジニアを募集しております。このようなモデル検証やアルゴリズム実装、実際のサービスへの組み込みまで、 一緒に当社のAI開発を推進していただける方は是非こちらの募集情報もご覧ください!
エンジニアリングマネージャー/AI・機械学習 | エンジニア職種紹介 | 株式会社ラクス キャリア採用
AIエンジニア | エンジニア職種紹介 | 株式会社ラクス キャリア採用
参考文献
[1] T.Kil et al., “Towards Unified Scene Text Spotting based on Sequence Generation”, https://arxiv.org/pdf/2304.03435v1.pdf
[2] Y. Huang et al., “LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking”, https://arxiv.org/pdf/2204.08387.pdf
[3] G. Kim et al., “OCR-free Document Understanding Transformer”, https://arxiv.org/pdf/2111.15664.pdf
[4] Papers With Code, https://paperswithcode.com/sota
[5] Scene Text Detection on Total-Text, https://paperswithcode.com/sota/scene-text-detection-on-total-text
[6] Scene Text Recognition on ICDAR2015, https://paperswithcode.com/sota/scene-text-recognition-on-icdar2015
[7] Document Layout Analysis on PubLayNet val, https://paperswithcode.com/sota/document-layout-analysis-on-publaynet-val
[8] Document Image Classification on RVL-CDIP, https://paperswithcode.com/sota/document-image-classification-on-rvl-cdip
[9] Key Information Extraction on CORD, https://paperswithcode.com/sota/key-information-extraction-on-cord
[10] Visual Question Answering (VQA) on DocVQA test, https://paperswithcode.com/sota/visual-question-answering-on-docvqa-test
*1:state-of-the-art モデル、最先端の高い性能を達成しているモデル
