
はじめに
こんにちは!
今年も国内外様々な LLM(大規模言語モデル)が公開されましたね!
LLM の選定や調査・実験をする際、リソースの要求レベルが非常に高く、ローカル環境での実施はかなりハードルが高いですよね...
そこで今回は、Google Colab(正式には Colaboratory)を利用して LLMを動かす方法を紹介します。
サクッと LLM を動かしたい時におすすめです!
Google Colab
Google Colab は、Google が提供している提供しているサービスで、ブラウザで Python を実行できるツールです。
機械学習の用途で利用されることが多く、操作も簡単です。
基本的な使い方
今回は、calm2-7b-chatを Google Colab 上で動かしてみましょう!
このモデルは、株式会社サイバーエージェント様が公開されているモデルです。
ライセンス区分は商用可能なApache License 2.0です。
前提:Google アカウントがあること
Google Colab にアクセス
Welcome To Colaboratoryにアクセスすると、Google Colab の画面が表示されます。
新規ノートブックを作成
左上のタブ 「ファイル > ノートブックを新規作成」 をクリックします。
新しいノートブックの画面が開かれますので、適当に名前をつけます。
私は
calm2-7b-chat.ipynbとしました。
ノートブックを新規作成 ノートブックの設定変更
続いて LLM を動かすためのリソース設定をします。
デフォルトではリソースに CPU を利用することになっていますが、このままではリソース不足のため実行途中で処理が打ち切られてしまいます。
左上のタブ 編集 > ノートブックの設定 をクリックすると、ダイアログが表示されます。
ダイアログの項目「ハードウェア アクセラレータ」のラジオボタン「T4 GPU」を選択します。
ダイアログ下部の 保存 ボタンをクリックして設定を保存します。

ノートブックの設定 
ハードウェアアクセラレータ これで準備は完了です!
では実際にコードを書いて動かしましょう!
コードを書いて実行
LLM を動かすために必要な Python ライブラリを事前にインストールしておきましょう。
公式に記載のライブラリはこちらに記載がありました。
※ LLM によって利用するライブラリやバージョンが異なることがあります。
まず、一行目に
pip install transformers accelerate bitsandbytesと入力します。そして入力フィールド左部の実行ボタン(▷)をクリックします。

ライブラリのインストール すると、インストールが進みしばらくすると完了します。
続いて、LLM を実際に動かすためのコードを書きます。
先ほどインストールが完了した次の行に、以下の実行コードをペーストします。
そして入力フィールド左部の実行ボタン(▷)をクリックします。
import transformers from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer assert transformers.__version__ >= "4.34.1" model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b-chat", device_map="auto", torch_dtype="auto") tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b-chat") streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True) prompt = """USER: AIによって私達の暮らしはどのように変わりますか? ASSISTANT: """ token_ids = tokenizer.encode(prompt, return_tensors="pt") output_ids = model.generate( input_ids=token_ids.to(model.device), max_new_tokens=300, do_sample=True, temperature=0.8, streamer=streamer, )prompt =に続く箇所がプロンプトですね。また、
output_idsでパラメータの調整ができます。たとえば、
temperatureパラメータを変動させることで、回答にランダム性を持たせることができます!ひとまず、サンプルプログラムを実行してみましょう!

途中経過 AIによって私達の暮らしはどのように変わりますか?という質問を投げかけています。モデルのダウンロードとプログラムの実行が完了するまでしばらく待ちましょう...
しばらくすると、結果が返ってきました!

サンプルプログラムの解析結果 ほかにも質問してみました!
質問:日本で2番目に標高が高い山はどこですか?
回答:日本で2番目に標高が高い山は、南アルプスの北岳(山梨県と静岡県にまたがる)で、標高は3,193メートルです。
今までのLLMはこの手の質問が苦手だったのですが、calm2-7bは正確ですね!

追加の質問
エラーがでたときは?
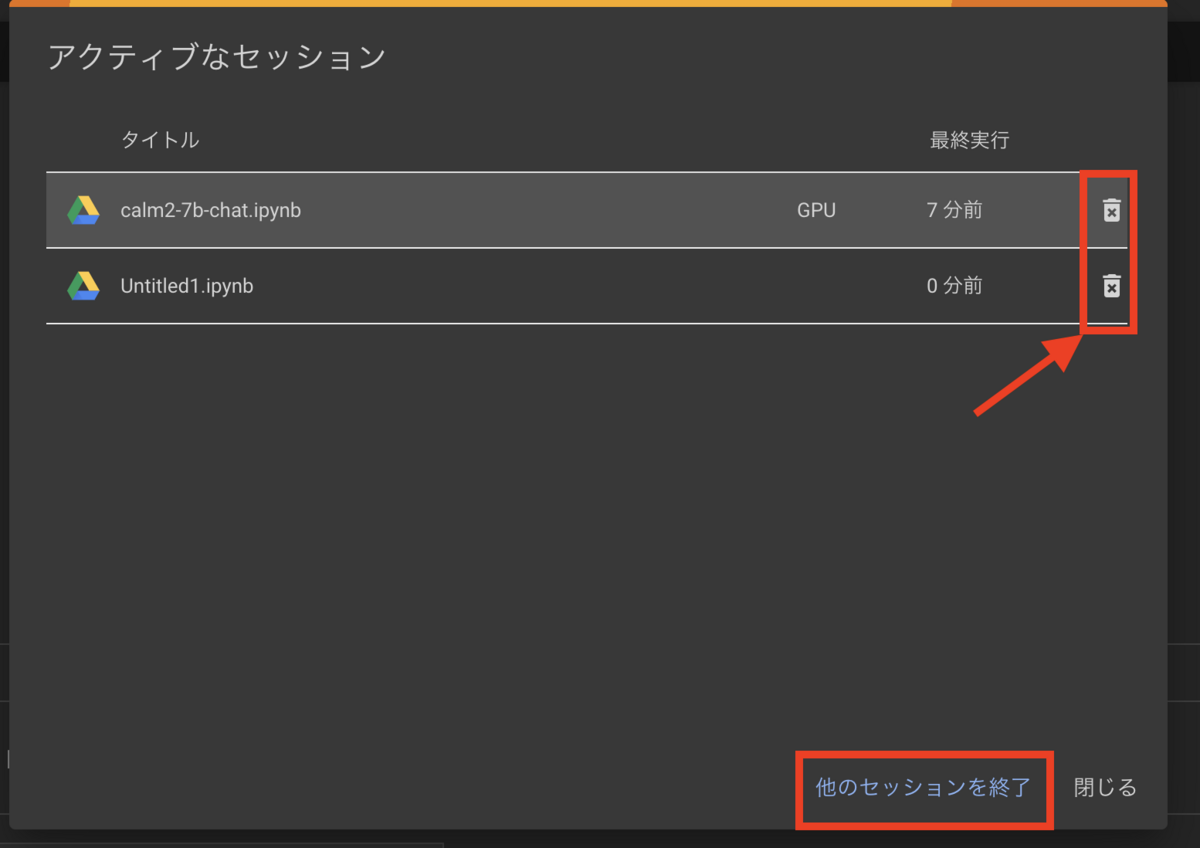
セッションが多すぎるとき
複数のタブで異なるノートブックを操作すると、どれか一つだけに絞るように促されます。

この場合は、ダイアログ右端のゴミ箱アイコンクリックで不要なセッションを閉じましょう。
なぜかうまく動かない時
必要な設定も行なっているし、必要なライブラリもインストールしているにも関わらずエラーが出る時があります。
その場合は、「ランタイム > セッションを再開しすべて実行する」をクリックしてみてください。


有料プランについて
先ほどのコード実行後のリソース状況を見てみましょう。
プロジェクト右上の項目「T4 RAM ディスク」をクリックします。
プロジェクト下部に自身が利用したリソースが表示されます。


GPU RAMがかなり逼迫していることが分かります。
無料枠だとリソースにかなりの制限があり、LLM を 1 度動かすのが限界です。
リソースのリセットタイミングも不明なので、ちょっと色々試したい場合は不便ですね...
ほかにも 12 時間経過すると実行環境が初期化されるなど、多くの制約があります。
有料プランに移行することでこうした問題を解決できます。
Google Colab のプラン選択画面にアクセスします。
いくつかプランがありますが、ちょっと試したいなという時はPay As You Goプランがオススメです。
このプランは、従量課金制ですので「解約忘れによる課金」が発生しません!
「コンピューティングユニット」と呼ばれるリソースを購入し、それを使い切るまで利用できる仕組みです。
これにより GPU の利用上限数をストックできます。
また、利用できる GPU の選択肢が広がります。
GPU の性能は、T4 < V100 < A100 となっていますが、性能が高いほどコンピューティングユニットを多く消費するため注意が必要です。
サクッと LLM を試してみるだけであれば T4 もしくは V100 でも十分だと思います。
各 GPU ごとの1時間あたりのコンピューティングユニット消費量の予測についてはリソース内に情報があるので確認してみてください。
| 1時間あたり | |
|---|---|
| T4 | 1.96 |
| V100 | 5.36 |
| A100 | 13.08 |

実際にPay As You Goを選択し、100 コンピューティングユニットを購入してみました。


購入後のリソース状況を見てみましょう。

コンピューティングユニットが増えていることが確認できますね!
ほかにも使ってみる
ほかにもいくつか日本語LLMを紹介します!!
ELYZA-japanese-Llama-2-7b
株式会社ELYZA様が公開しているLlama 2をベースとした日本語LLMモデル。 GPT-3.5 (text-davinci-003)」に匹敵するレベルを持つとのことです!
Youri 7B
Llama2 7Bをベースにしたrinna株式会社様の日本語LLMモデル。 400億トークン継続事前学習したモデルとなっており非常に高いスコアが出ていますね! rinna.co.jp
houou
マネーフォワード株式会社様が公開しているYouri7Bに対してチューニングを行ったLLMモデル。 インストラクションデータを使った学習により、回答の精度が大幅に向上したとのことです!
Swallow
東京工業大学が公開しているLLMモデルで、Llama2が苦手としていた日本語の読み書き性能が大幅に向上したとのことです! パラメータを調整することでオタクっぽくなることがネットでも話題になっていましたね!
東工大が昨日公開した日本語特化LLM『Swallow』を早速試してる。大学のシンボルマークであるツバメが名前になっているのも感慨深い。
— ヤマゾー@AIエンジニア (@yamazombie1) December 20, 2023
………これ、どんな深刻な話題もオタク特有のハイテンションな怪文書に変形されるんだけど、もしかして日本人を全員オタクにする計画はじめようとしてる…? pic.twitter.com/layDqlnKVL
ここ半年だけでも本当に多くの取り組みがなされていますね!
いつかLLMをさくっとローカルで動かせる時代がくれば...なんてのも、実はllama.cppというLLMがあります。
こちらは確かにCPUだけで動作するので本当にすごいです!!
(が、日本語の読み書きがやや弱く返答に中国語が混じったりします...)
2024年もLLMの動向ををウォッチしてどんどん試してみましょう!!
