 顔の濃さが唯一のアイデンティティのインフラエンジニア、m_yamaです。15カ月ぶり2度目の登場です。
顔の濃さが唯一のアイデンティティのインフラエンジニア、m_yamaです。15カ月ぶり2度目の登場です。
去年、ラクスで先行技術検証を行っている「技術推進プロジェクト」で取り組んだ「スケーラブルな監視システム」について、1年たっぷり寝かせた熟成リリースとなります。お目汚し失礼いたします。
- VictoriaMetricsとは?
- VictoriaMetricsのメリット・デメリット
- VictoriaMetricsの導入方法
- VictoriaMetricsの活用事例
- VictoriaMetricsでログは見れないの?
- まとめ
VictoriaMetricsとは?
VictoriaMetricsは、オープンソースの時系列データベースと監視ソリューションです。 Prometheusと互換性があり、設定ファイルをそのまま使えたりもするので、プロメテウサーは違和感なく利用できるはず。
ちょっと強い表現になってしまいますが、個人的にはPrometheus上位互換のOSS監視ツール、と感じています。
そんなVictoriaMetricsには、2つのバージョンがあります。
- single nodeバージョン
- clusterバージョン
ざっくり主要な機能をまとめてみました。以下のグレーバックのコンポーネントをまとめたのがsingle nodeバージョン、分割したのがclusterバージョンになります。 (他にもalertやproxyなどの便利そうなコンポーネントがいくつかあります)

clusterバージョンはマイクロサービスでナウいのでこちらの方が良さそうですが、公式としては100万データポイント/秒以下ならsingle nodeバージョンを勧めています。
It is recommended to use the single-node version instead of the cluster version for ingestion rates lower than a million data points per second.
https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html
一般的なnode_exporterの場合、1サーバで700メトリクスとちょっとあったので(※)、デフォルトの収集間隔の1分をもとにざっくり単純計算すると、監視対象が7万台ぐらいならsingle nodeバージョンで良さそうです。
※ AmazonLinux2023の場合
1,000,000(メトリクス/秒) / 800(メトリクス/サーバ) = 1,250(サーバ/秒)
1,250(サーバ/秒) * 60(秒) = 75,000(サーバ/分)
もちろんそんなバランスよくタイミングをずらしてデータ収集できるわけはないので要検証ですが、冗長化すればかなりの台数を監視できそうではあります。
VictoriaMetricsのメリット・デメリット
VictoriaMetricsのメリット
- Prometheusと互換性がある
- Grafanaから見る分には違いはない
- データ圧縮効率が高く、長期保存に向いている
- TimescaleDBと比べて最大70倍
- Prometheusと比べて最大7倍
- Prometheusで1TBのデータが120GBまで減ったとの記事もあり
- (clusterバージョンの場合) コンポーネントがわかれておりスケーラビリティに優れる
- スケールアウト・インが可能
- vmselect: 読み込み。複数人がたくさんのグラフを一度に取得しようとしたときにスケールアウトすればスムーズに読み込まれる(はず)
- vminsert: 書き込み。監視対象が増えて監視データが増えても手動で追加する必要なし
- スケールアウトのみ可能
- vmstorage: データ保存。重いクエリがたくさん来てもスケールアウトすればスムーズな処理ができる。はず。
- ※スケールインはデータロストを伴うので、計画的な拡張が必要
- スケールアウト・インが可能
- (clusterバージョンの場合) マルチテナントをサポート
- 複数システムの一元管理もしやすい
VictoriaMetricsのデメリット
- 日本語での導入事例が(Prometheusよりも)少ない
- コンポーネントが多くやや複雑
※デメリットに関してはあまり情報を見つけられず、推しが強めな内容になってしまっています。。
みなさんが検証する時に、ダメな点をぜひ教えてください(他力本願)
VictoriaMetricsの導入方法
VictoriaMetricsで監視を始めるには、やることが3つあります。
- VictoriaMetricsそのものの構築
- 監視対象にexporterをインストール
- vmagentのセットアップ
ここではシンプルなsingle nodeバージョンで話を進めます。
1. VictoriaMetricsの構築

single nodeバージョンのVictoriaMetricsは1バイナリで動くので、githubからダウンロードして実行するだけで起動します。
# ダウンロード curl -sLO https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.94.0/victoria-metrics-linux-amd64-v1.94.0.tar.gz # 解凍 tar xzf victoria-metrics-linux-amd64-v1.94.0.tar.gz # 実行 ./victoria-metrics-prod -storageDataPath=/path/to/data -retentionPeriod=1y
こんだけ。わー簡単。(本番運用するならサービス化とかログとか必要だけども)
起動オプションはいろいろありますが、公式曰く、基本的にデフォルト値を使えば十分、とのことです。助かる。
また公式でansibleのplaybookも用意されているので、clusterバージョンで複数台のnodeを使う場合は、こちらをベースにコード化しておくと楽そうです。
さらにさらに、各コンポーネントには公式のdocker imageもあるので、k8sとかECS Fargateでも監視クラスターを構築できそう。EFSをマウントしてデータをそこに入れれば、ほったらかしサーバレス監視システムができそう?やってみたい人生だった。
2. 監視対象にexporterをインストール
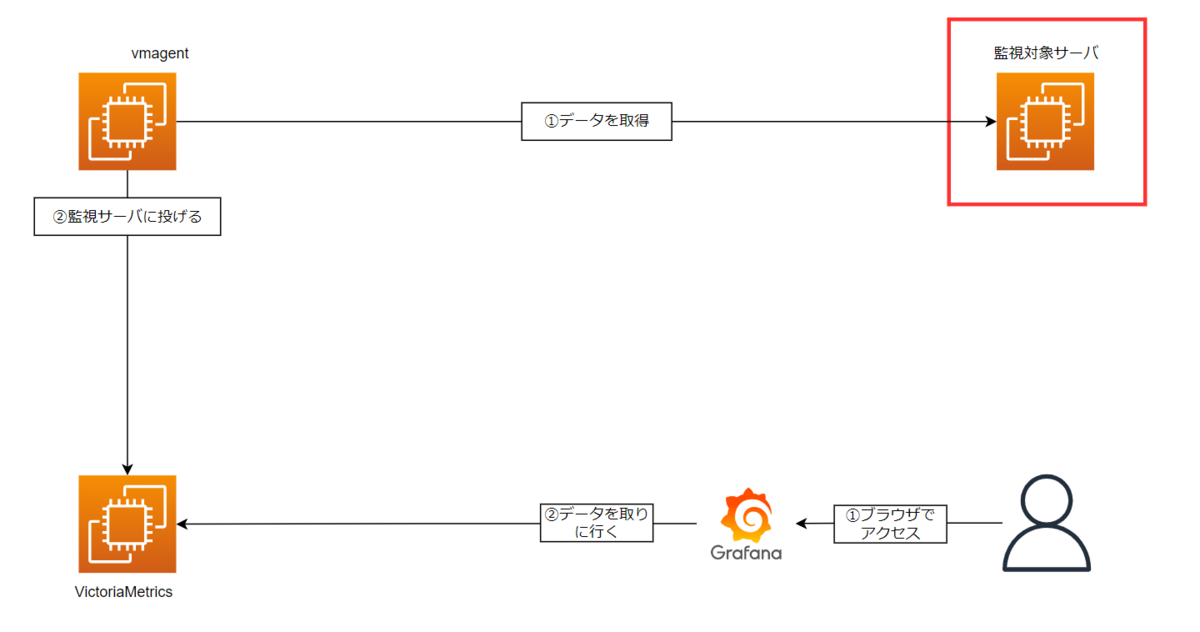
監視対象のサーバには、目的に合ったexporter(node_exporter、postgres-exporterなど)をインストールする必要があります。
手順(というにはシンプルすぎるけど)は以下の通り。
curl -sLO https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz ./node_exporter-1.6.1.linux-amd64/node_exporter &
こんだけ。わー簡(以下略)
その後、{サーバのIP or ホスト名}:{exporterのポート}/metrics にアクセスすると以下のようなデータが取得できます。
# node_exporterの場合
[ec2-user@hoge-server ~]$ curl -s localhost:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.1403e-05
go_gc_duration_seconds{quantile="0.25"} 3.1403e-05
go_gc_duration_seconds{quantile="0.5"} 3.1403e-05
go_gc_duration_seconds{quantile="0.75"} 3.1403e-05
go_gc_duration_seconds{quantile="1"} 3.1403e-05
go_gc_duration_seconds_sum 3.1403e-05
go_gc_duration_seconds_count 1
※基本的なメトリクスの取得に使われるnode_exporterでは、CPUやメモリなど700ちょっとのメトリクスをリアルタイムで取得できました。
そのメトリクスを、vmagent(後述)が定期的に取得しにくるので、監視対象でやることはexporterを起動しておくだけ。簡単。
exporterも監視対象に個別にインストールとかだと白目剥いちゃうので、ansibleでコード化しておきたいですね。
3. vmagentのセットアップ
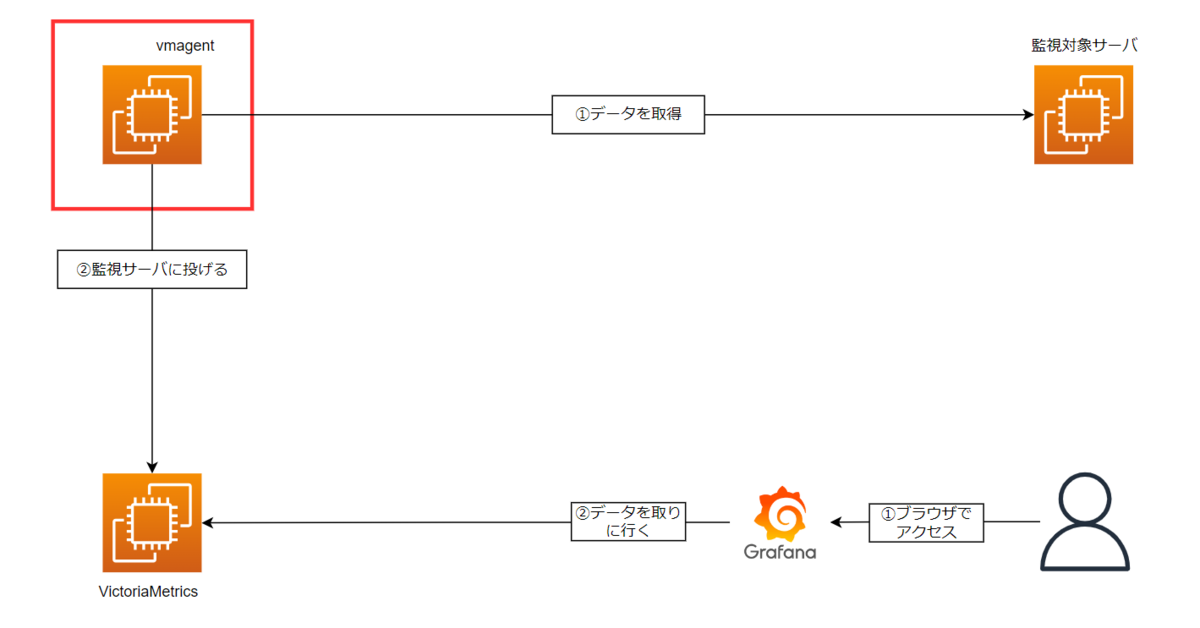 監視サーバと監視対象サーバの準備ができたら、監視対象サーバから上記のメトリクスを取得してVictoriaMetricsに投げるやつが必要です。それがこのvmagentです。
監視サーバと監視対象サーバの準備ができたら、監視対象サーバから上記のメトリクスを取得してVictoriaMetricsに投げるやつが必要です。それがこのvmagentです。
さっきとほぼ同じなので書くほどでもないのですが、一応導入手順を書いておきます。 (vmagentはvmutils-*に含まれる複数のバイナリのうちの一つです)
curl -sLO https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.94.0/vmutils-linux-amd64-v1.94.0.tar.gz
tar xvf vmutils-linux-amd64-v1.94.0.tar.gz
./vmagent-prod -promscrape.config=/path/to/prometheus.yml -remoteWrite.url=https://{victoria-metrics}/api/v1/write
こ(以下略)
configには監視対象や設定を記載します。詳しくはPrometheusのconfigurationを。
調べると、vmagentではなくPrometheusを使っている事例が多いのですが、Prometheusに比べてvmagentの方がメモリやCPU、ディスクIO、ネットワーク帯域幅を抑えることができるそうです。
すでにPrometheusを使っていてvmagentに乗り換える場合は、Prometheusの設定ファイルを使えるので移行も簡単。(Prometheus単独で使ってきた場合、設定ファイルにremote_write.urlでVictoriaMetricsを指定する必要はあります)
VictoriaMetricsの活用事例
コロプラ(colopl)の場合
累計データポイントが1,500億以上のk8sクラスターの監視にVictoriaMetricsを利用しているそうです。Prometheusではスケールアップしても耐えきれなかった負荷試験を、VictoriaMetricsでは安定してクリアできたとのこと。
(4年前の情報なので、さらに進化を遂げていそう)
Adidasの場合
事例というよりPromCon2019(Prometheusに関連するカンファレンス)で紹介されたPoC的な内容のようですが、Prometheusのリモートストレージとしても検討される時系列DBのInfluxDBやThanosと比較して、圧倒的にリソース消費量が少ないことがわかります。
https://promcon.io/2019-munich/slides/remote-write-storage-wars.pdf
CyberAgentの場合
2020年時点で、30以上のKubernetesクラスタを横断監視しているとのこと。プロダクトの増加による追加コストを抑えられている、というのは、Prometheusのサービスディスカバリとか省エネなリソース消費的な話かな?
(新卒で入社後半年でこの内容はすごい。。)
VictoriaMetrics+Prometheusで構築する複数Kubernetesの監視基盤 - Speaker Deck
FIFA ワールドカップ カタール 2022の監視にも導入されていた模様。GMP(Google Managed Prometheus)のサブ的な使い方?
大規模イベントを支えるクラウドアーキテクチャの実現 / ABEMA Cloud Platform Architecture for Large-scale Events - Speaker Deck
VictoriaMetricsでログは見れないの?
これまでは名前の通り、メトリクスに特化した監視システムで、ログを見る場合はElasticsearchやGrafana Lokiなどを利用する必要がありました。が、2023/7にvictorialogsがプレビューリリース(v0.1.0)され、ログまでまとめて管理できるようになりそうです。(2023/10/13点でv0.4.1が最新)
公式によると、victorialogsは、ElasticsearchやGrafana Lokiと比べて、最大で30倍のデータを処理できる、とのことです。すごい。
現在携わっているblastmail, blastengine(宣伝)でも、Elasticsearchのログやindexが肥大化してあっぷあっぷなので、こういった新しいツールも上手く活用できればいいなあ、というお気持ちです。
まとめ
OSS監視のVictoriaMetricsについてまとめました。SaaSの監視システムの料金が無視できなくなってきたらぜひ検討してみてください。
