
皆様こんにちは。インフラエンジニアのryuhei55225です!
学生時代は微生物の研究をしておりましたが、新しいことをやりたいと思い2019年にラクスに新卒入社し、現在は楽楽精算のインフラ基盤運用から各種デプロイまでを担当しております。
特技は野球とサッカーです。
球技なら何でも得意です。(ということにしておきます。)
IT技術を勉強し始めたのはラクスに入社してからなので、インフラエンジニア歴は約2年半になります。
今回はそんな私でも使うことが可能な、Kibanaに関してです。
今回の記事では「Kibana入門」ということで、Linux上にKibana+Logstash+ElasticsearchをインストールしてKibanaが使用出来るまでの手順を紹介したいと思います!
※Logstashはおまけです、Logstashの詳細な使い方については次回以降記載します。
今回使用するサービスについて
まずは、ざっくりKibana,Logstash,Elasticsearchについて説明していきます。
これらは、どれもElastic社によるサービスで、無償でも使うことが可能なサービスとなっております。
ということで、各サービスについてもう少し詳しく紹介していきます。
Elasticsearch
Elasticsearchは、様々なユースケースを解決する分散型RESTful検索/分析エンジンです。
データを一元的に格納することで、超高速検索や、関連性の細かな調整、パワフルな分析が大規模に、
手軽に実行可能になります。
https://www.elastic.co/jp/elasticsearch/
Elasticsearchは、分散型で無料かつオープンな検索・分析エンジンです。
テキスト、数値、地理空間情報を含むあらゆる種類のデータに、そして構造化データと非構造化データの双方に対応しています。
Apache Luceneをベースに開発されたElasticsearchは、2010年にElasticsearch N.V.(Elasticの前身となる企業)がはじめてリリースしました。
シンプルなREST APIや分散設計、スピードとスケールの優位性で広く浸透したElasticsearchは、現在もElastic Stackの中核となるプロダクトです。
Elastic Stackはデータ投入からエンリッチメント、保管、分析、可視化までを実現する無料かつオープンなツール群です。
Elasticsearch、Logstash、Kibanaの頭文字をとった"ELK Stack"の愛称でも知られています。
Kibana
Kibanaは無料かつオープンなユーザーインターフェイスです。
Elasticsearchデータを可視化したり、Elastic Stackを制御することができます。
https://www.elastic.co/jp/kibana/
Kibanaは無料かつオープンなフロントエンドアプリです。
Elastic Stackを統括して管理し、Elasticsearchでインデックスされたデータに、検索と可視化の機能を提供します。
一般的には“Elastic Stackで使えるチャート作成ツール”として知られています。
一方で、KibanaはElastic Stack(Elasticsearch、Logstash、Kibanaの頭文字から以前は“ELK”と呼ばれることもありました)
クラスターの監視や管理、保護のためのユーザーインターフェースとして、さらに、Elastic Stackに搭載されている各種ソリューションの一元的なハブとしても活躍します。
2013年にElasticsearchコミュニティで誕生して以来、KibanaはElastic Stackの開かれた窓として、多くのユーザーと組織にポータルとしての機能を提供しつづけています。
Logstash
Logstashは、無料かつオープンのサーバーサイドデータ処理パイプラインです。膨大な数のソースからデータを取り込み、変換して、好みの格納庫(スタッシュ)に送信します。
https://www.elastic.co/jp/logstash/
Logstashは、リアルタイムのパイプライン機能を備えたオープンソースのデータ収集エンジンです。
Logstashは、異なるデータソースのデータを動的に統合し、そのデータを選択した出力先に合わせます。
多様で高度なダウンストリーム分析と可視化の事例向けにすべてのデータをクレンジングし、誰でも使えるようにします。
本来、Logstashはログ収集における革新を牽引していますが、その機能はその事例に留まりません。
収集プロセスをさらにシンプルにする多数のネイティブコーディックにより、数多くのinput、filter、
およびoutputのプラグインであらゆる種類のイベントを整形し変換することができます。
Logstashは、大量かつ多様なデータを利用して、分析を促進します。
やりたいこと
ということで、今回は上記のサービスが利用可能なサーバを構築していきたいと思います。
以下のように、外部サーバから観覧可能なKibanaサーバを構築します。
そして、簡単なCSV形式のデータをグラフ化してみたいと思います。
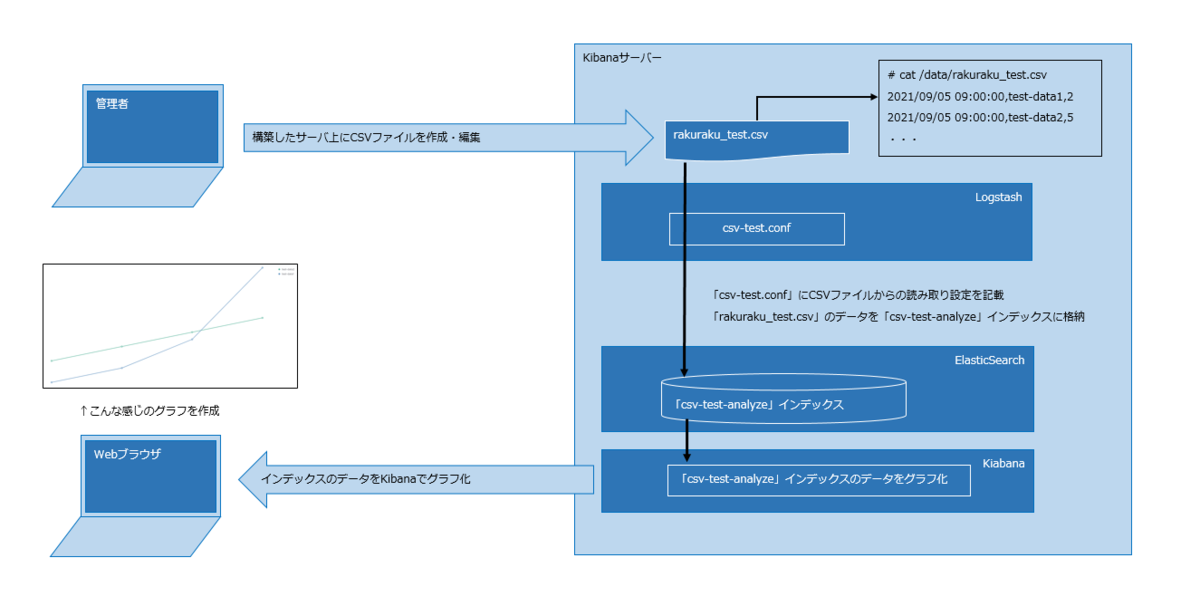
構築した環境
※Elastic製品のバージョンは揃えております。(2021年10月時点では、7.15.0まで出ているようです。)
▼今回の仮想サーバスペック
- CPU:2コア
- メモリ:4GB
- HD:20GB
構築手順
さあ、これから実際にサーバの構築をしていきたいと思います。
今回は初歩的なOSインストールから実施しておりますので、分かる方はインストール手順までスキップして下さい。
OSインストール
CentOS7をインストールし初期設定をする
(1)ホスト名設定
(2)IPアドレス設定(DefaultGatewayなどを含む)
(3)DNS設定
(4)NTP設定
等々、構築する環境に合わせて設定していきます。
いつものやつ(RPMの最新化)
# yum update -y # reboot
Kibanaを使用するにあたって、minimalインストールした際のRPMのバージョンは何でも問題ないので、 とりあえず、最新バージョンに上げておきましょう。
Kibana,Logstash,Elasticsearchのインストール
まずは、公式サイトよりモジュールを取ってきます。 サービスのインストール方法は様々ありますが、今回はRPMをサーバに直接配置してlocalインストールする方法で実施しました。
※yumコマンドを使用することでコンパイル等を意識せず、サーバから直接外部ネットワークに出る必要もないので、最も簡単だと思います。
今回利用したRPM
https://artifacts.elastic.co/downloads/kibana/kibana-7.13.4-x86_64.rpm https://artifacts.elastic.co/downloads/logstash/logstash-7.13.4-x86_64.rpm https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.4-x86_64.rpm
※バージョンについては、最新バージョンで試すのもありかと思います。
(1)上記rpmをダウンロードしてサーバの/tmpに配置する
(2)yum installする
#yum localinstall /tmp/kibana-7.13.4-x86_64.rpm #yum localinstall /tmp/logstash-7.13.4-x86_64.rpm #yum localinstall /tmp/elasticsearch-7.13.4-x86_64.rpm
Elasticsearchの起動
では、実際にインストールしたサービスを起動していきたいと思います。
ただ、そのまま起動しても上手く起動しないサービスもありますので、少し設定を確認しながら起動していきます。
ということで、まずはデータを格納して検索するためのElasticsearchを起動していきます。
(1)Javaのインストール
Elasticsearchの起動にはjavaが必要になってきますので、まずはjavaをインストールします。
※Elasticsearchサービス内のjavaを使用して(デフォルト)起動することも出来ますが、チューニング等はしずらいので、openJDKをインストールしておきます。
# yum install java-1.8.0-openjdk
(2)Javaの環境変数設定
インストールしたjavaに合わせて、設定ファイルのパスを修正します。
# vim /etc/sysconfig/elasticsearch 以下に修正 --------------------------------------- ES_JAVA_HOME=/usr/lib/jvm/jre ---------------------------------------
(3)スワップの無効化
ElasticSearchは公式で「起動時にメモリを確保し、スワップしないようにする」という設定が推奨されています。
ということで、systemdの起動ファイルを少し修正します。
# vim /usr/lib/systemd/system/elasticsearch.service [Service]セッションに以下を記載する ---------------------------------------- LimitMEMLOCK=infinity ---------------------------------------- # systemctl daemon-reload
合わせて、yamlファイルも修正します。
# vim /etc/elasticsearch/elasticsearch.yml 以下のコメントアウトを外します。 ---------------------------------------- bootstrap.memory_lock: true ----------------------------------------
以下のコマンドを実行して、「"mlockall" : true」となっていれば設定が反映されております。
※サービス起動後に確認
# curl http://localhost:9200/_nodes/process?pretty
(4)外部サーバからのアクセス許可設定
デフォルトの設定では、Elasticsearchを起動しても外部サーバから検索エンジンを使用することが出来ません。
そのため、以下のyamlファイルを編集して、外部サーバからのアクセスを許可します。
# vim /etc/elasticsearch/elasticsearch.yml 以下のパラメータになるよう修正します。 ---------------------------------------- network.host: 0 discovery.seed_hosts: ["サーバのIPアドレスを記載"] cluster.initial_master_nodes: ["サーバのIPアドレスを記載"] ----------------------------------------
(5)Elasticsearchサービスの起動
サービスの起動と自動起動設定を追加します。
# systemctl start elasticsearch.service # systemctl enable elasticsearch.service
ここまでやれば、ブラウザから「http://設定したIPアドレス:9200/」でElasticsearchの情報が観覧可能となります。
※Elasticsearchの情報はJSON形式での応答となります。
Kibanaのサービス起動
続いてKibanaサービスの起動です。
(1)外部サーバからのアクセス許可設定
Elasticsearchと同様に設定ファイルを編集します。
# vim /etc/kibana/kibana.yml 以下のパラメータになるよう修正します。 ---------------------------------------- server.host: 0.0.0.0 ----------------------------------------
(2)Kibanaサービスの起動
サービスの起動と自動起動設定を追加します。
# systemctl start kibana.service # systemctl enable kibana.service
これで、「http://サーバのIPアドレス:5601/」でkibanaのホーム画面が観覧可能となります。
この時点で手動でデータを入れたり、検索出来たります。
※楽楽メモ
ブラウザでポート番号を意識したくない人はapacheをインストールし下記proxy設定をいれておくと便利です。
---------------------------------------- ProxyPass / http://localhost:5601/ ----------------------------------------
Logstashのサービス起動
(1)設定ファイルの作成
/etc/logstash/conf.d/下にインデックスを作成するための設定ファイルを作成します。
今回は、CSVファイルからインデックスを作成する設定ファイルを作成しました。
※詳細は次回以降説明します。
# cat /etc/logstash/conf.d/csv-test.conf
input {
file {
path => "/data/rakuraku_test.csv"
start_position => "beginning"
type => "csv-test-analyze"
}
}
filter {
if [type] == "csv-test-analyze" {
csv {
columns => [
"date"
, "text"
, "number"
]
separator => ","
}
date {
match => [
"date"
, "YYYY/MM/dd HH:mm:ss"
]
}
mutate {
convert => {
"number" => "float"
}
}
}
}
output {
if [type] == "csv-test-analyze" {
elasticsearch {
hosts => ["localhost:9200"]
index => "%{type}"
}
}
}
(2)CSVファイルの作成
次に実際にLogstashで読み込むためのCSVファイルを作成します。
(1)の設定ファイルで指定した「/data/rakuraku_test.csv」に以下のようなデータを記載します。
# cat /data/rakuraku_test.csv 2021/09/05 09:00:00,test-data1,2 2021/09/05 09:00:00,test-data2,5 2021/09/12 09:00:00,test-data1,4 2021/09/12 09:00:00,test-data2,7 2021/09/19 09:00:00,test-data1,8 2021/09/19 09:00:00,test-data2,9 2021/09/26 09:00:00,test-data1,18 2021/09/26 09:00:00,test-data2,11
(2)Logstashサービスの起動
サービスの起動と自動起動設定を追加します。
# systemctl start logstash.service # systemctl enable logstash.service
→Logstashを起動した時点で、新しく「csv-test-analyze」というインデックスが作成されて、CSVファイルに記載したデータが、このインデックスにインポートされます。
今回の検証ではLogstashを利用して実データをインポートすることになります。
ただ、手動でJSON形式で入れるなど、Elasticsearchにデータを入れる方法はいろいろあります。
Kibanaでグラフの作成
今回は文字数の関係上、グラフを作成する手順については割愛させて頂きますが、上記手順で作成した「csv-test-analyze」インデックスをグラフ化することで以下のようなグラフを表示することが出来ます。
※こちらの手順にもついても次回のブログで記載させて頂きます。
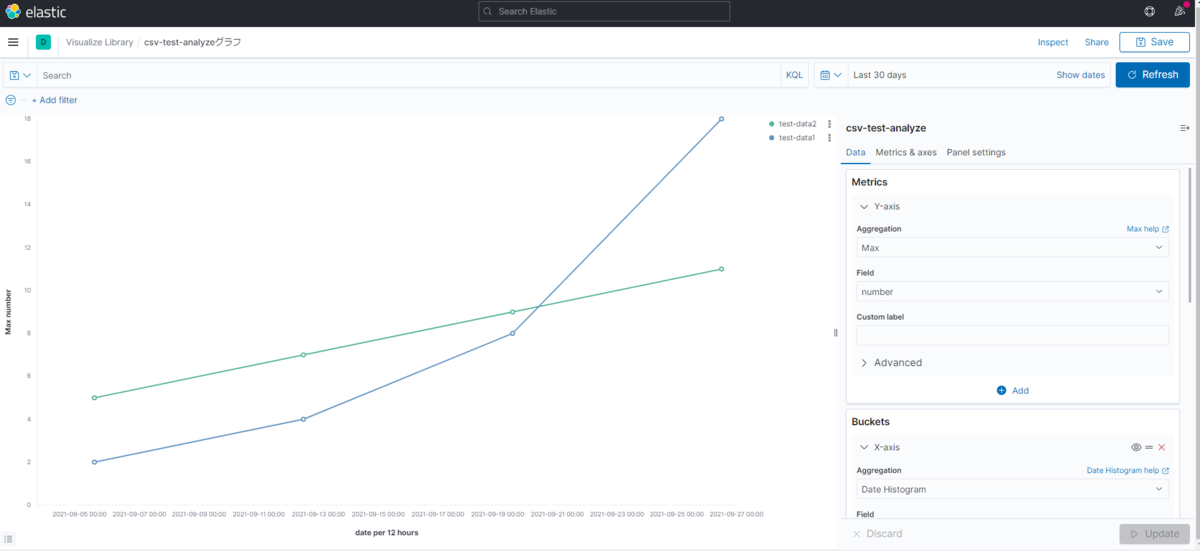
ということで、お疲れ様でした!これでKibanaでのグラフの表示が出来ました!
今回はシンプルなデータのためKibanaのメリットを感じにくい内容となっておりますが、データが複雑になればなるほど、Kibanaで出来ることは増えていきますので、ぜひ皆さん試してください!!
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
forms.gleイベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください! rakus.connpass.com
