
はじめに
こんにちは。SREの gumamon です!
NewRelic、Datadog、モダンな監視ツール(オブザーバビリティ)って良いですよね。弊社もKubernetes(k8s)等を利用した環境が増えてきた折、そろそろ必要になってきたのですが、NewRelic、Datadog等のクラウドサービスはランニングコストが高くなりがちです。 では内製できないかやってみよう!・・・というようなことを昨年度から取り組んでいたのですが、やっとこさ形になりましたので改めてブログで紹介させて頂こうと思います。
今回ご紹介するのは、大まかなシステムの構成と設計時の観点です。各コンポーネントの詳細や工夫できた点などについては、改めて別の記事でご紹介できればと思います。 また、「オブザーバビリティとは?」や「試行錯誤の過程」については、以前執筆した以下のブログをご参照ください。
目次
全体構成
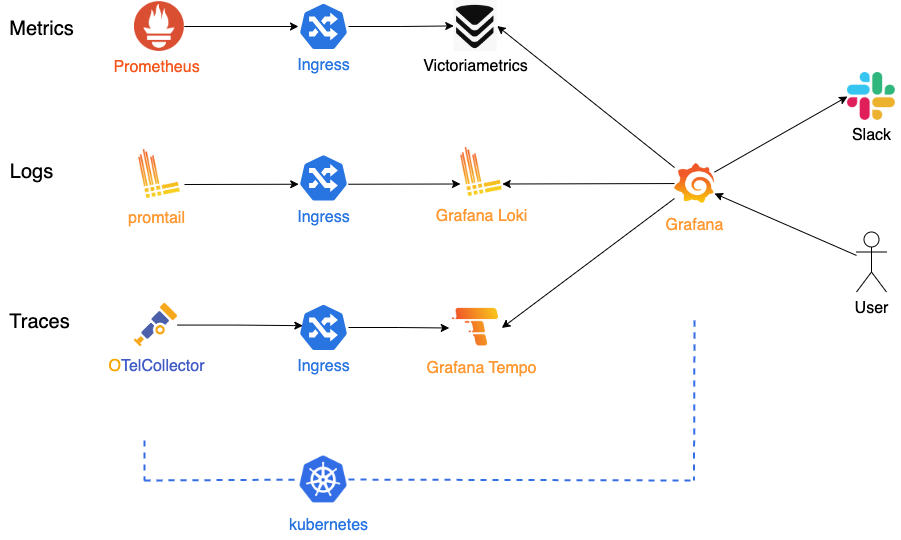
さっそくですが、今回構築した環境の全体像は以下のとおりです。
※k8s上にデプロイしています
今回の設計では下記を重視しています。
- ユーザーの認知負荷を低く保つこと
- 変更容易性が高いこと
それぞれのポイントについて、設計観点を記載します。
設計観点:ユーザーの認知負荷を低く保つ
ユーザーインターフェイスはGrafanaに統一
何かを確認したいときに、あちこち情報を探すのは面倒です。このため、テレメトリを見たい=Grafanaを見れば良い、という導線になるようにインターフェイスを統一しました。今回の構成では複数のサービスが連携してオブザーバビリティを提供していますが、ユーザーが見るのはGrafana(とSlack)のみです。
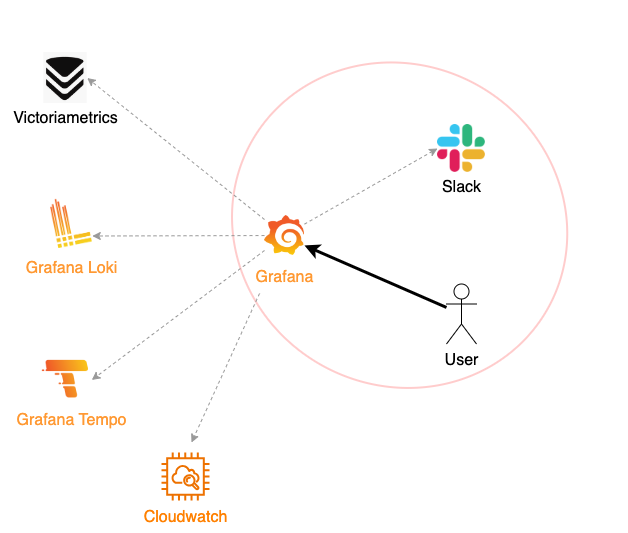
この統一が実現できたのは、Grafanaの設計理念のおかげです(私はこの考え方がとても気に入り、Grafanaを中心にアーキテクチャを構築しました)。
Grafanaの設計理念は Big Tent Philosophy と呼ばれています。 「データがどこにあってもアクセスでき、観測可能性戦略に最適なツールを選択できるべきだ」という考えが根底にあり、Grafanaはプラグインベースのアーキテクチャを採用しています。
その結果、多くのデータソースに対応するプラグインがコミュニティや企業で開発されており、Grafana上でほぼ何でも可視化できるという状況が生まれました。
Prometheus , Loki , OpenTelemetory , Cloudwatch , Datadog , PostgreSQL ... etc
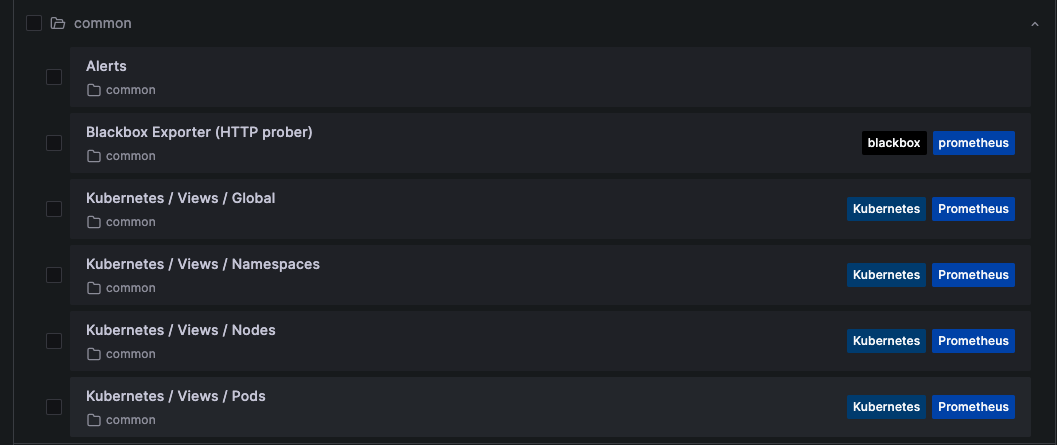
プリセットのダッシュボードとアラート
サービスの増減に伴うGrafanaのメンテナンスも面倒です。そのため、SREがプリセットのダッシュボードやアラートを管理・提供し、ユーザーが自身で作りこむ必要がないようにしました。 ただし、これはGrafanaの優秀さだけではなく、オブザーバビリティを提供する対象がk8s上のサービスだったことも幸いしています。k8sはコアコンポーネントがPodやService、PersistentVolume等のメタ情報を持っているので、多くのメトリクスを容易に収集することができます(ログも決まったところに決まった形式で出力されてきます)。これらを先に述べたダッシュボードやアラートに紐づけることで、SRE側も無理なくk8s環境全体のオブザーバビリティを提供できています。
Dashboards
Dashboards AlertRules
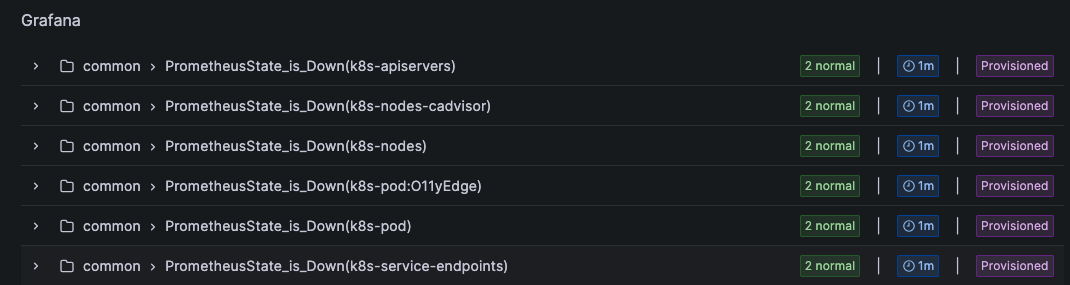
AlertRules
設計観点:変更容易性を高く保つ
今回の構成ではアーキテクチャ選定に悩みました。PoCやステークホルダーとの議論で「とりあえずこれでよさそう」となりましたが、より良い選択肢が後から見つかる可能性も十分にあるため、将来的に「やっぱり変えます」が容易にできる構成にしたいと考えました。各コンポーネントが疎結合になるよう、以下の軸で整理しています
テレメトリの種別ごとにパイプラインを水平分割する
Metrics, Logs, Traces は、それぞれ異なる性質を持つテレメトリです。
- 取得目的が違う
- 取得方法が違う
- 通信規格が違う
- 負荷のかかるタイミングが違う
そのため、各テレメトリを独立させ、シンプルに扱える構成としました。初歩的な実装ならばオールインワンのエージェントを導入する方が楽ですが、運用の柔軟性を高めるのであれば、Prometheusなどの草分け的なOSSをテレメトリごとにそのまま使う方が最終的には楽だと判断しました。また、異なる種類のメトリクスを同一サービスに集約しないことにもこだわりました。これにより、どれか一つを別のサービスに置き換えたい場合の移行がスムーズに行えます。
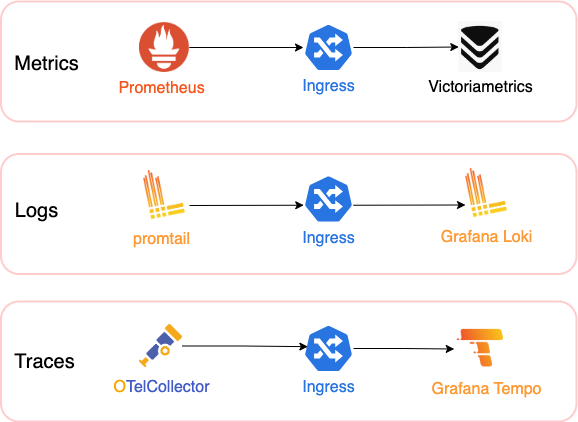
PrometheusはPull型のアーキテクチャですが、別のPrometheus Serverへメトリクスをリレーする
RemoteWrite機能を持っています。PrometheusとVictoriaMetrics間の通信は、このRemoteWriteを用いて実現しています。
目的別(テレメトリ収集・集約)にIngressを挟んで垂直分割する
今回の主な監視対象はk8s上のサービスです。k8sはClusterやNodeが増減するため、データ収集を行うエージェント(Edge)と、データ集約を行う中央集権的なサービス(Central)は多対一の関係になります。このため、中央集権的なサービスの前にIngressを配置し、エージェントはIngressのエンドポイントにテレメトリデータをPushする構成にしました。
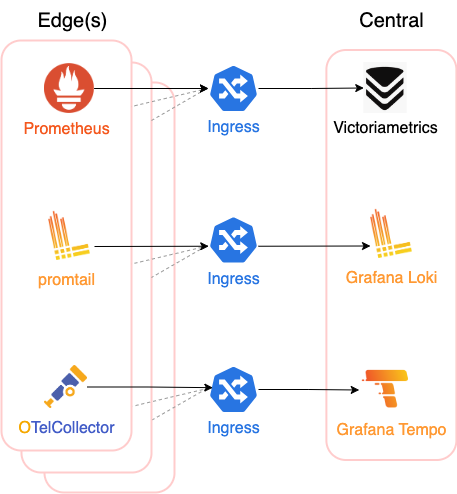
Edgesは必ずしもk8sである必要はありません。(ある程度手作業にはなりますが)通常のLinux環境などからも、エージェントを配置することで情報を集約可能です。
まとめ
今回は Grafana Stack x OpenTelemetryを使ったオブザーバビリティ構成についてご紹介させていただきました!
同じようなチャレンジをされている方の一助となれていましたら幸いです。
なお、今後の展望としては・・・
- フロントエンド監視やプロファイル監視を追加したい
- SLI・SLOをいい感じに設計して行きたい
- Traceについてはまだまだ改良をしていきたい(SLI・SLOとも深く関連してくる)
以上、最後までお読み頂きありがとうございました!
