みなさんこんにちは。フジサワです。前回の記事でお伝えしていたElasticsearchの検証がひと段落しましたので、検証結果をレポートいたします。
連載目次
- 『全文検索 〜 Elasticsearchとデータ匿名化手法』
- 『全文検索の探求 Elasticsearch(1) 』: プロジェクト方針およびElasticsearch概要
大量データを検索するサービスでElasticsearchはRDBの代替候補になりうるか?(Elasticsearch vs pg_bigm)』 ←今読んでいる記事
- データ匿名化 第2回:個人情報は匿名化しても意味がないのではないか?
- データ匿名化 第3回:個人情報を匿名化するプロセス
- データ匿名化 第4回:匿名化のために行うデータ項目の一般化とは
- データ匿名化 第5回:データ匿名化の指標
- データ匿名化 第6回:実際の匿名化
はじめに
検証を行うにあたり、私たちは前回、以下の通りゴール設定をしました。
『検索機能を有する新規サービスのアーキテクチャ検討段階で、RDBだけでなくElasticseachが比較検討材料として挙がる状態を作る』
この検証を行うにあたり、以下のようなサービスをモデルとして設定しました。
- 扱うデータのレコード数は、多くても100万件オーダー
※当社はBtoB向けのサービス、かつ中小企業のお客様を主たる顧客層としているので、1顧客でウン千万件、ウン億件というようなレコードが発生するケースよりは上記程度のデータ量が検証対象としては妥当だろうと判断しました。 - テキストデータに対する、中間一致検索(いわゆるLIKE検索)機能を持つ
※従来の技術領域を代替するもの、という位置付けでRDBでパフォーマンス劣化が発生しがちな中間一致検索を採用
また、当社ではRDBにPostgreSQLを採用する場合が多いのですが、デフォルトのPostgreSQLでは比較の余地がないので、PostgreSQLの全文検索プラグインであるpg_bigmを比較対象として採用することにしました。
結論から言うと…
- 「従来型のLIKE検索を行う代替手段」としては、速度・機能面でElasticsearchは候補になりうる。しかし、その目的だけであれば、pg_bigmを採用するほうがデメリットが少なく、わざわざElasticsearchを導入する必要は無い。
- Elasticsearchを採用するのであれば、形態素型インデックスの特徴を活かした「自然な文書検索」や「あいまい検索」、「スケーラビリティ」などの要件を重視するべきである。
- いずれを選択するかは、機能要件・用途や、データの特性に応じて選択をすべきである。
以下、上記結論に至った検証結果をご覧ください。
データストアとしての振る舞いの特徴
検証結果をお伝えする前に、Elasticsearchのデータストアとしての特徴を確認しておきましょう。
ドキュメント型データベースである
- ElasticSearchはドキュメント型データベースで、自由なレイアウトでのデータ表現が可能です。スキーマにとらわれず、様々な形式の文書データを横断的に検索することに優れています。
スケーラブル
- Elasticsearchはデータセットを分割の最小単位となるシャードに分け、複数のノードにシャードを分散して配置します。シャードを動的に再配置することで柔軟にスケールアウトさせることができます。
トランザクションがない
- Elasticsearchにはトランザクションがありません。データの登録に失敗した、登録中に他プロセスから検索がかかった、といったACID性を求められる局面では別途考慮が必要です。
結合は不得手
こうした特徴から単純にRDBの代替として採用するというよりは、大量の文書を高速に検索することに適した仕組みを活かして、限定的に使用するのが良いでしょう。
検証:PostgreSQLのLIKE検索と同じ検索結果を得ることができるか
Elasticsearchを使用した場合でも、PostgreSQLのLIKE検索と同様の結果を得ることができるのでしょうか。
結論から言えば、PostgreSQLのLIKE検索と同様の検索結果を得ることができることが分かりました。
ただし、Analizerについての前提知識とその特性について理解したうえで、match_phraseクエリを使用する必要があります。
Analizerとは
Elasticsearchにおける、文書データ、および検索クエリ文字列を分解・加工することで効率よく検索を行うための仕組み。
文書データをインデキシングする際、「一定のルール」に従って文字列を分割する。
検索クエリに対しても同じルールで文字列を分割し、分割された状態で検索を行うため、1バイトずつ探索を行うのに比べて、高速に検索を行うことができる。
この、「一定のルール」を司るのがTokenizerと呼ばれるもので、形態素解析型、N-Gram型(文字列をN文字長分割する)などがある。
文書データをどう扱いたいのかによって、どのようなAnalizerを選択するかを決定する必要がある。
形態素解析型を用いたAnalizer(Kuromoji Analysis Plugin)の場合
形態素解析型を用いた場合、「全文検索エンジン」という文字列は次のように分割されます。
curl -X POST -k -H 'Content-Type: application/json' '/_analyze' --data '{
"analyzer" : "kuromoji",
"text" : "全文検索エンジン"
}'
{
"tokens": [{
"token": "全文",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
}, {
"token": "検索",
"start_offset": 2,
"end_offset": 4,
"type": "word",
"position": 1
}, {
"token": "エンジン",
"start_offset": 4,
"end_offset": 8,
"type": "word",
"position": 2
}]
}
N-gram型のAnalizerの場合
N-gram型を用いた場合、「全文検索エンジン」という文字列は次のように分割されます。 なお、検証に使用したAmazonESには、N-gram型のAnalyzerがありませんので、自分でTokenizerを指定してカスタムAnalyzerを定義しています。
curl -X PUT -k -H 'Content-Type: application/json' '/bigram' --data '{
"index":{
"analysis":{
"tokenizer" : {
"bigram" : {
"type": "nGram",
"min_gram" : 2, "max_gram" : 2,
"token_chars": [ "letter", "digit" ]
}
},
"analyzer" : {
"bigram" : {
"type" : "custom",
"tokenizer" : "bigram"
}
}
}
}
}'
curl -X POST -k -H 'Content-Type: application/json' '/bigram/_analyze' --data '{
"analyzer" : "bigram",
"text" : "全文検索エンジン"
}'
{
"tokens": [{
"token": "全文",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
}, {
"token": "文検",
"start_offset": 1,
"end_offset": 3,
"type": "word",
"position": 1
}, {
"token": "検索",
"start_offset": 2,
"end_offset": 4,
"type": "word",
"position": 2
}, {
"token": "索エ",
"start_offset": 3,
"end_offset": 5,
"type": "word",
"position": 3
}, {
"token": "エン",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 4
}, {
"token": "ンジ",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 5
}, {
"token": "ジン",
"start_offset": 6,
"end_offset": 8,
"type": "word",
"position": 6
}]
}
上記において、例えば「エンジ」というキーワードで検索を行った場合、形態素型のAnalizerを用いた場合はHitせず、N-gran型のAnalyzerを用いた場合はHitします。
もし、Elasticsearchを、RDBの代替としてLIKE検索と同等の検索を行うのであれば、N-gram型のAnalyzerを使用することで実現できます。
一方で、形態素型のAnalyzerを使用する方が、検索結果としてはより自然な検索結果を得ることができます。
今回は、LIKE検索の代替という観点で検証するためN-gram型を採用しましたが、Analyzerの選択については、本来は下記の基準で選ぶことになります。
なお、Elasticsearchは、複数のAnalyzerを複合的に用いることもできますが、これについては今回の検証内容からは外しています。
match_phraseクエリ
Elasticsearchを用いて全文検索を実行する際、どのような問い合わせを実行するかを指定することができます。
matchクエリは、指定したクエリ文字列をAnalizerによって分解し、それぞれのトークンの順序によらず、トークンが含まれているかどうかによって検索結果を導出します。
GET /_search
{
"query": {
"match" : {
"message" : {
"query" : "全文検索エンジン"
}
}
}
}
例えば、「全文検索エンジン」というキーワードで問い合わせを行った時、AnalyzerにKuromojiを使用していれば、検索キーワードは全文、検索、エンジンという3つのトークンに分割されます。
この時、「全文検索エンジンとは」という文章だけでなく、「エンジンが全文を検索します」という文章も、検索結果にHitします。
一方、LIKE検索のような中間一致検索にElasticsearchを使用したい場合は、match_phraseクエリを使用する必要があります。
GET /_search
{
"query": {
"match_phrase" : {
"message" : {
"query" : "全文検索エンジン"
}
}
}
}
match_phraseクエリは、それぞれのトークンの順序・出現位置が一致するものを検索結果に導出します。
ですから、「全文検索エンジンとは」という文章はHitしますが、「エンジンが全文を検索します」や、「全文を検索するエンジンです」といった文章はHitしません。
検証:PostgreSQL(pg_bigm)と比較してどれだけの検索性能が発揮できるか
次に、Elasticsearchとpg_bigmの検索速度の比較による検索性能の検証結果を見ていきましょう。
pg_bigmとは?
- PostgreSQL上で動作する日本語に対応した全文検索用モジュール
- N-gram方式で、2文字単位で分割する
- インストールやインデックスの構築が容易
- SQLをそのまま利用できる
- 公式ドキュメント
検証に使用したデータ、およびデータ量
- Wikipediaの日本語版全データ
- データ件数:約230万件
計測方法
- 無作為に選定したキーワード群からランダムに選定したキーワードを用いて1000回問い合わせを行い、問い合わせに要した時間(ネットワーク経路に係る時間などを除く)と、対象のキーワードでHitした文章の数をグラフにプロットする
- Elasticsearch、pg_bigmを適用したPostgreSQL、無調整(B-treeインデックス)のPostgreSQLの3者に対して同様の検索を行い、グラフを比較する
計測に使用した環境
- それぞれの検証に使用した環境およびスペックについては下記の通りです。なお、Elasticsearchは最小構成でも3ノードを要するうえ、ElasticsearchもPostgreSQLも、チューニングによって性能が変わるため、厳密にスペックを揃えることはしていません。(※傾向を掴むことを主目的としています)
- Elasticsearch
- PostgreSQL(pg_bigm)
- Amazon EC2上にPostgreSQLをインストール(RDSではpg_bigmがサポートされていないため)
- v9.6(PostgreSQL)
- v1.2(pg_bigm)
- インスタンスタイプ:t2.large × 1ノード
- PostgreSQL(デフォルト)
- Amazon EC2上にPostgreSQLをインストール
- v9.6(PostgreSQL)
- インスタンスタイプ:t2.large × 1ノード
計測結果と考察
まずはデフォルト(B-treeインデックス)のPostgreSQLの計測結果を見てみます。キーワードやそのキーワードのHit件数によらず、最低でも50秒以上の時間を要することがわかります。これは、キーワードによらず、シーケンシャルスキャン(テーブルの全レコードの走査)が行われるため、一定の時間がかかっていることが要因です。
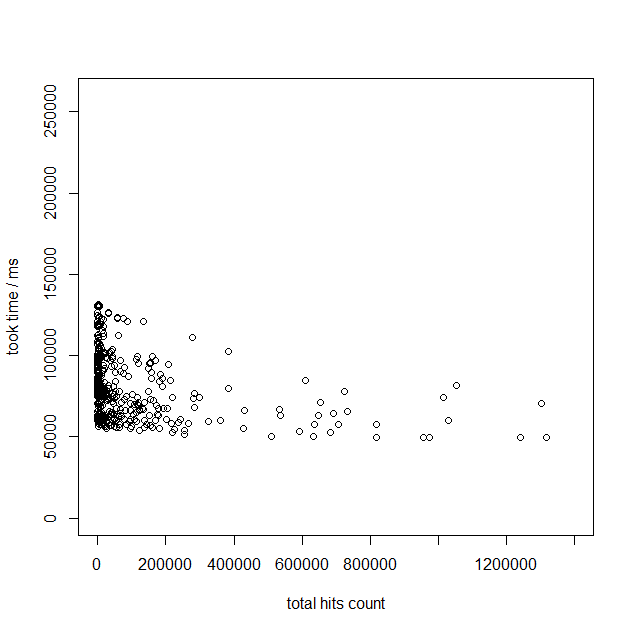
次に、同一のスケールの場合のElasticsearchとpg_bigmの計測結果を見てみましょう。
この結果を見ると、双方、キーワードにHitするレコードの数に応じて速度が遅くなっている事が分かります。デフォルトのPostgreSQLが固定でシーケンシャルスキャンのコストがかかっているのに比べると、高速化が見込めることが分かります。しかし、キーワードHit数が多くなるにつれて、検索速度がかなり遅くなっていくようです。場合によっては、デフォルトのPostgreSQLと同等のパフォーマンスになるケースがあるようにも見えます。
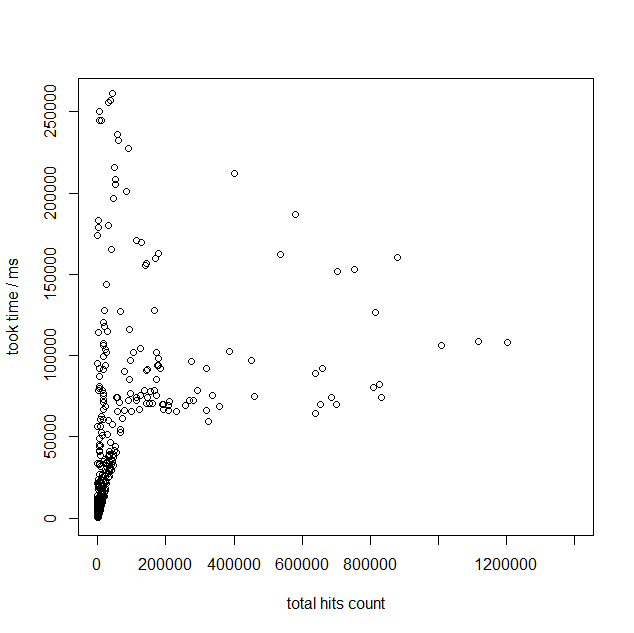
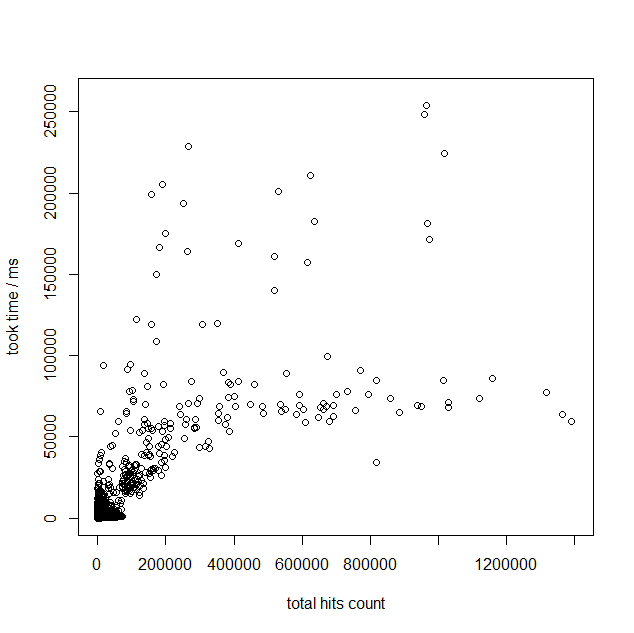
※なお、このグラフを見ると、pg_bigmの方が高速であるように見えますが、これは検証に使用した環境の性能差によるものだと考えられます。ここでは詳細を述べませんが、Elasticsearchのノード数を増やす、インスタンスタイプのグレードを上げることで、検索速度が向上することが確認できています。
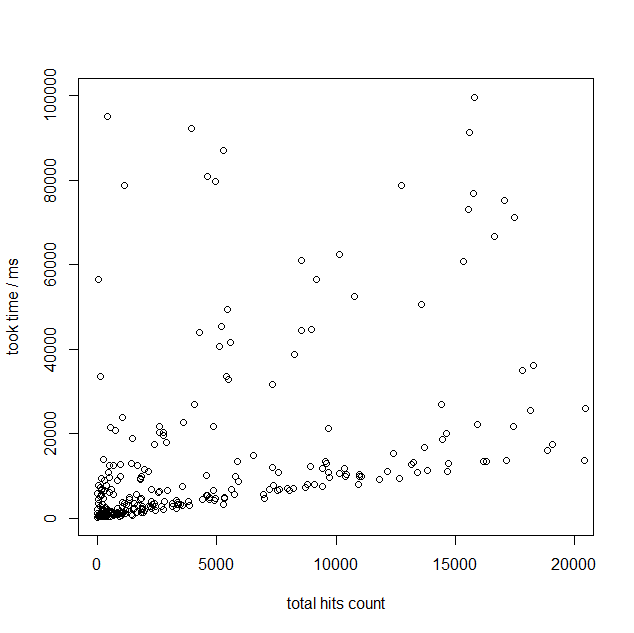
先ほどのスケールでは分かりにくいので、もう少し拡大したグラフで計測結果を見てみましょう。 これを見ると、Hit件数が少ない場合(1000件~2000件程度)であれば、遅くとも数秒以下の速度で検索結果が得られているようです。
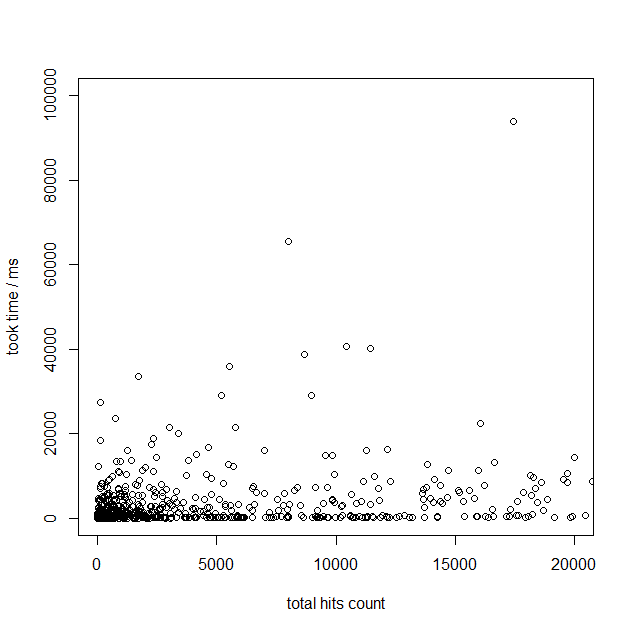
では、次のデータを見てみましょう。これはElasticsearch,pg_bigm双方で、「検索キーワードにHitした先頭10件」を検索するのに要した時間です。試行回数は1000回、単位はmsecです。
| Elasticsearch | pg_bigm | |
|---|---|---|
| 平均値 | 9 | 75 |
| 中央値 | 10 | 25 |
| 最大値 | 159 | 3641 |
これを見る限り、最大値こそpg_bigmで少し遅い結果が得られていますが、平均値・中央値を見る限り、「キーワードにHitする件数によらず、全体から先頭の少数の結果を取得することは、十分に高速な速度で実行できる」ということが分かります。
つまり、ここまで見てきた結果から、Elasticsearch, pg_bigmはいずれも次の傾向であると言えると考えられます。
- キーワードにHitする件数によらず、全体から先頭の少数の結果を取得することは、十分に高速な速度で実行できる
- キーワードにHitする件数が膨大で、そのすべての結果を得る場合はデフォルトのPostgreSQLと同等、ないしそれ以上の時間を要する
一般的に、膨大な検索結果を一度に取得するケースは少なく、ページネート機能や無限スクロール機能を持ったUIデザインを用いて、部分的に順次読みだしていくという利用シーンの方が多いと考えられるため、後者のデメリットが顕在化することはあまりないのではないかと考えられます。
以上から、検索速度という点においては、Elasticsearchとpg_bigmの間には決定的な差が無く、双方とも必要十分な検索性能を有するのではないか、という結論に達しました。
なお、今回は詳細に触れませんが、RDBでLIMIT-OFFSETを使用して、集合の後半の検索結果を得る場合、速度が遅くなるケースがあります(これはSQLチューニングなどで対応できます)。
この現象はElasticsearchでも同様で、これを解決する手段として、Elasticsearchは次のような機能をデフォルトで持っています。
- Search After
- ページネーションに最適化された検索方式で、検索結果を先頭ページから順次検索する際に利用できる
- Scroll
- 検索結果をキャッシュして、後から部分的に再利用できるようにする仕組み。初回のキャッシュ作成時は時間がかかる。
まとめ
Elasticsearchは『速度改善』だけで選ぶものではない
私たちは、当初Elasticsearchを導入することによって検索機能の速度改善が見込めるのではないかという仮説に基づき検証を進めてきましたが、速度改善だけを主目的として導入の判断をすべきではないということが分かりました。
従来型の検索方式や使い方だけで判断するのであれば、わざわざElasticsearchを導入する必要はなく、pg_bigmでも十分に速度改善を見込む事ができます。
Elasticsearchには次のようなデメリットがあり、必ずしも選定条件として優位とは言えません。
- Elasticsearchとpg_bigmを比較した場合のデメリット
- 学習コストがかかる
- 別のサーバーリソースを要する
- Elasticsearchを耐障害性なども考慮して使用する場合、最低でも3台のノードを必要とし、RDBとは別にリソースを確保する必要があります。
- 正規化できない、トランザクションがない
- 前述の通り、Elasticsearchは正規化や結合が苦手ですので、マスタDBを使用した絞り込みなどの用途には向いていません。
- また、トランザクションが無いため、ACID性を期待しないか、または、別途仕組みを講じる必要があります。
- この点においては、PostgreSQLと一体になっているpg_bigmの方が設計やデータの取り回しがしやすいと言えるでしょう。
※pg_bigmにも「インデックスサイズが大きくなる」「更新処理にオーバーヘッドが増える」というデメリットがありますが、これはElasticsearchを採用した場合と比較しての明確なデメリットとは言えないと考えています。
餅は餅屋である
では、Elasticsearchはどのようなシーンで採用するべきなのかというと、「Elasticsearchでしかできないこと」が開発するシステムの要件に含まれている場合だと考えています。具体的には、
- 自然言語で記述された大量の文書データに対して、より文章として自然な検索結果を得たい
- 検索キーワードを基にしたあいまいな検索結果を得たい
- システムの運用を継続するにつれて肥大化していくデータに対して、動的にクラスタ構成をスケーリングしたい
というようなシーンではないでしょうか。こうした点については、RDBでは対応が難しい場合が多く、文章の検索に特化したElasticsearchならではの活用範囲であると考えています。
つまり、従来型の検索方式の『代替』としての役割を期待することが間違っているのであり、Elasticsearchの得意分野、かつRDBでは代替できないところに採用することで、Elasticsearchの価値が享受できるということです。
最後に
今回の検証を行うまでは、ただ漠然と「Elasticsearchを使うと全文検索が速くなるらしい」といった程度の認識でしかありませんでしたが、検証を通して、Elasticsearchの特性や、活用範囲などを理解することができました。
今後、新規サービスのアーキテクチャを検討する段階で、Elasticsearchの特性がうまく適用できるかどうか、という点が、アーキテクチャ選定の材料にできると考えています。
今回の検証結果が、少しでも皆様のお役に立てば幸いです。
連載目次
- 『全文検索 〜 Elasticsearchとデータ匿名化手法』
- 『全文検索の探求 Elasticsearch(1) 』: プロジェクト方針およびElasticsearch概要
- 大量データを検索するサービスでElasticsearchはRDBの代替候補になりうるか?(Elasticsearch vs pg_bigm)』 ←今読んでいる記事
- データ匿名化 第1回:匿名化された個人情報とは何なのか
- データ匿名化 第2回:個人情報は匿名化しても意味がないのではないか?
- データ匿名化 第3回:個人情報を匿名化するプロセス
- データ匿名化 第4回:匿名化のために行うデータ項目の一般化とは
- データ匿名化 第5回:データ匿名化の指標
- データ匿名化 第6回:実際の匿名化
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
rakus.hubspotpagebuilder.comラクスDevelopers登録フォーム

https://career-recruit.rakus.co.jp/career_engineer/form_rakusdev/イベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください!
◆TECH PLAY
techplay.jp
◆connpass
rakus.connpass.com
