
こんにちは。インフラエンジニアの gumamon です!
近年、Kubernetes等の登場により、アプリケーションのスケールアウトはとても簡単になりました。対して、データベース(DB)のスケールアウトは依然として困難です。
「RDBMS」⇒ データの一貫性は保てるが、スケールアウトが難しい
「NoSQL」⇒ データの一貫性を保てないが、スケールアウトが容易
DBのスケールアウトを考えるとこの2択に行きつく、というのが今までの常識だったかと思いますが、
『どっちも!』が出来てしまう第3の選択肢が登場しました。
- データの一貫性を保て、且つスケールアウト容易な『NewSQL』!
最近、NewSQLの一つである yugabyteDB の検証をする機会がありましたので、アーキテクチャと検証結果を紹介します。
目次
ここがすごいぞ yugabyteDB!
はじめに、個人的なyugabyteDBの推しポイントを紹介します。 どれもインフラエンジニア目線では、垂涎の機能ばかりです。
◆PostgreSQL 完全互換である
内部構造的には全く別物でありながら、PostgreSQL11と(ほぼ)完全な互換性があります。
psqlコマンドでアクセスできますし、APPの接続先をPostgreSQLからyugabyteDBに変更するだけで利用可能です。
◆全ノード Read/Write 可能
yugabyteDBでは全てのノードに対してRead/Write可能です。RDBMSにおけるActive,Standbyのようなノード間の上下関係が存在しません。ノード構成時にレプリケーションの構成を考える必要もありません。
◆ノード故障に伴うダウンタイムゼロ
yugabyteDBはレプリケーション係数(以下 rep)という変数を持ち、その変数に応じてデータを複製します。例えば、rep=5 と設定した場合、データは5重に複製され、2ノードまでのノード故障に耐えることができます。さらに ノード故障から規定時間(デフォルトでは15分)を経過すると、生存しているノードのデータが別ノードに再度複製され、冗長性が回復します。つまり、99ノード(物理機)でクラスタを構築したとしてもノードの故障率を考慮する必要があまり無い、と言えます。
◆ノード追加・削除のダウンタイムゼロ
yugabyteDBは無停止でクラスタ構成の変更が可能です。
ノード削除 ⇒ 削除予定ノードでBlackListコマンドを打つと、データが他ノードに移動します。後は空になったノードを停止するだけです。
◆無料です
Apache2.0 ライセンスのOSSです。これだけの機能を持ちながら完全無料!
※有償のマネージドサービスもあります 。
yugabyteDBのアーキテクチャ
つぎに、yugabyteDBがどのように前述の機能を実現しているかを紹介していきます。全てを書き起こすと果てしない長さになってしまうので、今回はyugabyteDBの概要と、NewSQLの「肝」にフォーカスしてご紹介します。
詳しい情報は公式ドキュメント をご参照ください。読みやすいです!
キーコンセプト
yugabyteDBのアーキテクチャは階層化された設計になっています(2層構造)。
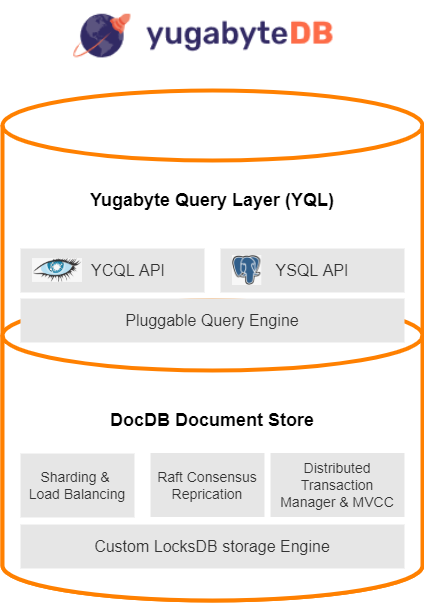
◆Yugabyte Query Layer
クライアントへの応答を返す上位層です。
特徴的なのは Pluggable QueryEngine です。これは APIをどんどん追加できるように設計されており、今後も新たなAPIが追加予定とのことです。(実際、初期のyugabyteDBはYCQLのみで、後からYSQLが追加されています。) RDBMS、NoSQLのインターフェイスを併せ持つDBというのは中々無いのでは?と思います。
◆DocDB Document Store
分散ドキュメントストアーです。
Raft Consensus Replication ⇒分散合意アルゴリズムを用いたレプリケーション(後述。NewSQLの肝①)
Sharding & Load Balancing ⇒テーブルシャーディング(後述。NewSQLの肝②)
DistributedTransactionManager&MVCC ⇒データの一貫性を担保。ACID特性を持つ
Custom RocksDB Storage Engine ⇒ Facebookにも採用されているKey-Valueストア
データ保管場所の実体はKey-Valueストアですが、これに3つのコンポーネントを追加することで、一貫性、可用性、分断耐性を併せ持つドキュメントストアとして機能しています。
NewSQLの肝①: Raft (分散合意アルゴリズム) とは?
ひらたく言うと、「柔軟に多数決を採決し、一貫した結論を出すアルゴリズム」と言えるかと思います。
Kubernetesを構成するコンポーネント etcd でも利用されており、「一貫性、可用性、分断耐性を併せ持つことはできない」とする「CAP定理」を打破することが出来ます。Raftでググると「よくわからない・・」という記事が沢山ヒットしてしまうのですが、やっていることは中々にシンプルです。ただ、静止画で説明をするのが難しいので詳しく知りたい方はこちらのサイトをご参照頂ければと思います。とても分かりやすいです!
以下ではアルゴリズムの肝になる部分のみ、かいつまんで説明してみます。
Raftの概要
クラスター構成
Leader x1 ⇒リーダー選挙に当選したnode。意思決定権を持つ
Follower x n ⇒リーダー選挙に落選したnode。意思決定権を持たない
主要な動作
リーダー選挙 ⇒Leader不在のクラスターで発生。Leaderを選出
ログ複製 ⇒Leaderの意思決定をWAL(Write Ahead Log)でFollowerに伝達(複製)
※重要なこと
NewSQLの肝②: Table Shardingとは?
ひらたく言うと、大きなテーブルを「メタデータ+テーブルxn」に「行」分割する機能と言えるかと思います。テーブルシャーディングを行うと、小分けにしたテーブルは検索性が向上します。また、異なるnodeに配置することで、ハードウェアリソースの負荷を分散することもできます。

テーブル分割は「分散キー」を元に、実行されます。yugabyteDBの場合、デフォルトではPRIMARY KEYをHASH化したものが「分散キー」となり、PRIMARY KEYの値に関係なくランダムに分割・配置します。特定のルールに従って分割・配置することも可能ですが、その場合は特定のnodeにアクセスが集中する「ホットスポット」が生まれやすくなるため、注意が必要です。 yugabyteDBでは、分割したテーブルのことをTablet(タブレット)と呼びます。
yugabyteDBにおける Raft , Table Sharding
yugabyteDBを rep=3 , node=4 で構成した例で説明をします。

上図はyugabyteDB内のあるテーブルです。テーブルのデータ(緑)が3つのタブレットに分割され、メタデータ(青)で管理されています。各タブレットは rep=3に従い、3重に複製されています。また、複製されたデータは各々Raftを形成しており、何れか1つのタブレットのみがLeaderとなっています。上図はyugabyteDBのDocument Storeの動作イメージです。この上位層に(4nodeにまたがる形で)Query Layerが展開されており、各nodeの何れかがクエリを受け取ると、Query Layerは対応するタブレットのLeaderにRead/Write命令を投げる、という仕組みになっています。nodeが増えるとクエリが分散される。nodeが増えずともタブレットが違えばクエリの並列実行が可能で、且つTransaction Managerによりデータの一貫性も担保される、という仕組みになっているようです。
yugabyteDBの検証結果
今回、とある弊社商材のDBをPostgreSQLからyugabyteDBに置換してみました(既存データの移設も含む)。サマリーですが、その結果を紹介してみたいと思います。
PostgreSQLとの互換性
完全互換と謳うだけあって、リリースレベルのテストを行ってもほぼ問題が発生しませんでした。ただ、実態はPostgreSQLを模したAPIであり、一部本家PostgreSQLと挙動が異なったのでご紹介です。
テーブルロック
PostgreSQLには多様なロックモードがありますが、yugabyteDBで現在実装されているのは ACCESS SHARE のみでした。その他ロックモードは開発中とのこと。
トランザクション競合時の挙動
PostgreSQL11でトランザクションが競合した場合、後発トランザクションは先行トランザクションが完了するまで待ってからCOMMITする動きをする(後勝ちとなる)のですが、yugabyteDBにおいては後発トランザクションにエラーが返ります。こちらも現在開発中とのこと。
データ移設
COPYコマンドですんなり移設できました。
前述したPRIMARY KEYのHASHが自動実行され、PostgreSQL上の元テーブル(1000万行)はバラバラのタブレットに分割されました。複合キーを使っていたテーブルについても問題なし。
可用性・分断耐性
この検証結果は素晴らしかったです!推しポイントにも書きましたが、node故障、追加、削除、ネットワークの分断(※)の発生において、ヒトが行うべき作業はほぼ何もありません。やるべきことは サービスの起動・停止 それだけです。
※yugabyteDBはAZ(Availability Zone)の概念を持っており、どのnodeがどのAZに所属しているかを設定する必要があります。これはネットワークの分断に備える為に重要なことです。例えばrep=3 , node=6のクラスタを3つのAZに2nodeずつ配置したとします。この際AZの設定をyugabyteDBにしていないと、node1,node2,node3でRaftを組むようなタブレットが出て来て、ネットワーク分断が発生した時、一部のタブレットのみ孤立しているAZ側で多数決を可決してしまう状況が発生する可能性があります。
まとめ
yugabyteDBのアーキテクチャ、検証結果について紹介させて頂きました!
yugabyteDBはRDBMS+NoSQLの良いとこ取りDB (NewSQL)
(ほぼ) PostgreSQL11完全互換
可用性・分断耐性は素晴らしい。データの再配置までしてくれる
yugabyteDBの知名度はまだまだ(?)なのですが、NewSQLであるCloudSpanner(GCP) やTiDB(OSS/MySQL互換)は国内でもちらほら導入事例を聞くようになって来ました。
CloudSpannerはドラクエウォーク等、巨大なリソースを必要とする(?)サービスにも採用されているようです。NewSQLのスケーラビリティ、可用性には未来を感じる・・!と個人的には思っています。当記事をご覧になり、気になった方はぜひ使ってみてください。今回はOS上に直接構築をしましたが、Kubernetesの知見がある方はHelmChartが出ているので、そちらを使った方がスムーズかなと思います。
以上、最後までお読み頂きありがとうございました!
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/
カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
rakus.hubspotpagebuilder.com
ラクスDevelopers登録フォーム

https://career-recruit.rakus.co.jp/career_engineer/form_rakusdev/
イベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください!
◆TECH PLAY
techplay.jp
◆connpass
rakus.connpass.com
