
こんにちは。 株式会社ラクスで先行技術検証をしたり、ビジネス部門向けに技術情報を提供する取り組みを行っている「技術推進課」という部署に所属している鈴木(@moomooya)です。
ラクスの開発部ではこれまで社内で利用していなかった技術要素を自社の開発に適合するか検証し、ビジネス要求に対して迅速に応えられるようにそなえる 「
2020年度は通年で「無停止リリース」について取り組んでいるので、途中ではありますが紹介したいと思います。
今までの記事はかみせんカテゴリからどうぞ。 tech-blog.rakus.co.jp
これまでの無停止リリースへの取り組み
これまで本ブログでも無停止リリースに関する記事を公開してきました。
今回これらを踏まえた上で検証結果をまとめることができたので改めて公開していきたいと思います。
前提
無停止の定義
ここでいう『無停止』とはエンドユーザーから見てサービスが止まっていないことを指します。
冗長化されたサーバークラスタのうち、再起動のために片系が停止するといったケースは許容します。
想定している運用
サービスカットオーバーから一度も停止せずに運用していく、といったことは目指しません。技術的にはできないこともなさそうですが、そこから発生する制約やコスト増などを考慮するとBtoBのビジネスを展開している弊社としては割に合いません。
目指している運用としてはほぼ毎回リリースのたびにサービス停止を伴っている現状から、年1回程度のサービス停止を伴うメンテナンスリリースと年数回~十数回のサービス停止が不要な通常リリースという運用に切り替えていければと考えています。
検討したシステム構成
全体像
システム構成自体は適用可能なサービスが多くなるよう、あまり特殊な構成にならないようにしました。DBプロキシの前段にクエリキューイングのレイヤを入れるなどすると、より対応可能な範囲が広がりそうではありましたが機能レイヤの追加コストと、必ず必要になるほどではないと考えて今回は見送っています。
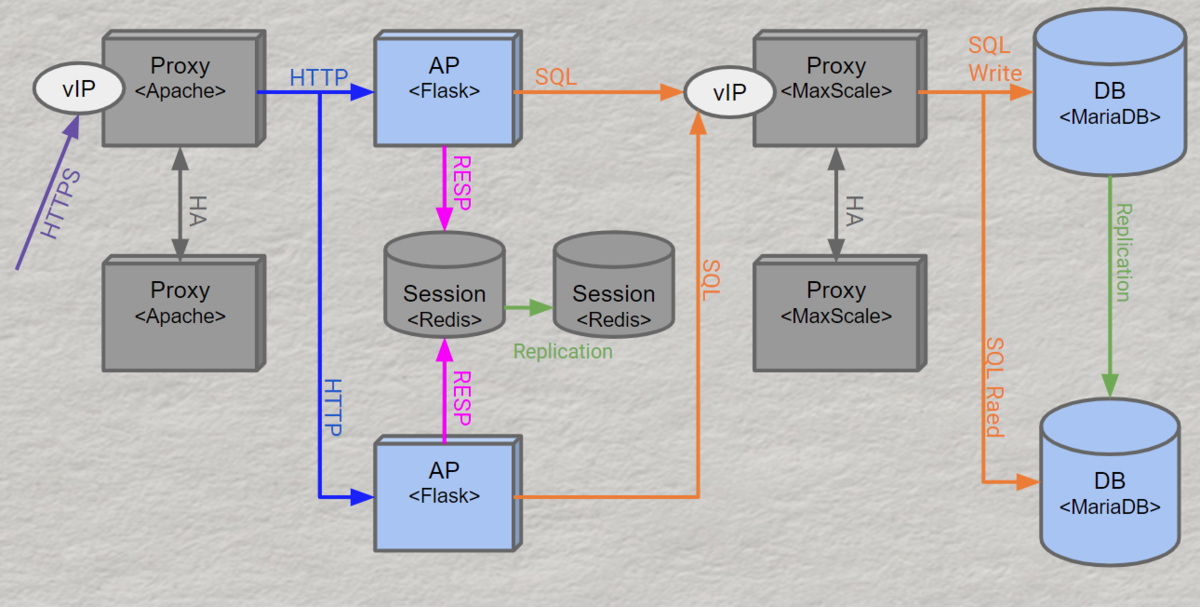
ポイント説明
DBプロキシにMariaDB MaxScaleを採用
DBのプライマリ、セカンダリの入れ替えなどを制御するためにDBプロキシとしてMariaDB MaxScaleを採用しました。 弊社のDBはPostgreSQLが多いのですが、DBMS自体がオンラインDDLへの対応など無停止に向けた機能が充実していたためMariaDB + MariaDB MaxScaleの構成を採用しています。 既存サービスへの適用としてPostgreSQLに適応させたDBプロキシについても後述します。
WEBプロキシにApacheを採用
昨今nginxが優勢になりApacheが過去のものという印象も多いかと思いますが、今回改めて再評価したところApache 2.4を採用することにしました。
Apache 2.2の頃までは1プロセスシングルスレッドでプロセスがたくさん立ち上がるせいでメモリ大食いという印象でしたが、今では1プロセスマルチスレッドで動作させることができるのでメモリ消費は大幅に抑えられています。
そして決め手となったのは、下流ノード(APサーバー)の死活チェックを業務リクエストと別でチェックすることができる、Active Health Checkが利用可能ということでした(nginxにもあるけど有償版が必要でライセンスが結構高い)。これを利用することによりAPサーバーの切り離しや復旧を、リクエストを取りこぼすことなく行うことができるようになります。
検証方法
リリース作業をHTTPリクエスト負荷をかけた状態で行って、HTTPリクエスト負荷にエラーレスポンスが含まれないことを目標に検証しました。
負荷のかけ方
負荷はJMeterで、認証、参照、更新の処理を用意して、秒間10リクエストの低負荷状態と秒間100リクエストの高負荷状態のパターンで検証しました。
JMeterの使い方については弊社ブログのこちらの記事もご参照ください。
シナリオ説明
検証したリリースシナリオは2つ。
ミドルウェアのバージョンアップ
APサーバーのミドルウェアとDBMSのアップデートを行います。これらは必ず再起動が必要となります。OSのアップデートについてもこのパターンでカバーできると判断しています。 処理中のリクエストを欠損させることなく、切り離しと復旧を行う必要があります。
操作は以下のように行いました。
- DB 2号機
- 切り離し
- DBMSアップデート
- 復帰
- DB 1号機の降格とDB 2号機の昇格
- DB 1号機
- 切り離し
- DBMSアップデート
- 復帰
- AP 2号機
- 切り離し
- ミドルウェアアップデート
- 復帰
- AP 1号機
- 切り離し
- ミドルウェアアップデート
- 復帰
APサーバーについては1号機2号機の違いは特にないので入れ替えても問題ないかもしれません。
4のDB昇格/降格についてはMariaDB MaxScaleのswitchoverコマンドを用いました。
アプリケーションとDB定義のアップデート
APサーバー上のアプリケーションバージョンのアップデートとDB上のテーブル定義変更を行います。また、アプリケーションは予期せぬリスクを考慮して本番環境でのホットリロードは行わず再起動を行います。テーブル定義変更は再起動を伴わずに実施します。
操作は以下のように行いました。
- プライマリDBにテーブル定義変更のSQL(DDL)を投入
- (セカンダリDBにはレプリケーションにより自動反映)
- AP 2号機
- 切り離し
- ミドルウェアアップデート
- 復帰
- AP 1号機
- 切り離し
- ミドルウェアアップデート
- 復帰
テーブル定義変更は以下の制約があります。

検証結果
おおむね期待通りに動かすことができたのですが……
『DBのプライマリ、セカンダリの入れ替え時に1秒だけ書き込みエラー』
1つ目のシナリオにて、DBサーバーのプライマリ、セカンダリの昇降格処理中に書き込みクエリに対してのみ1秒弱のエラーが発生しました。
MaxScaleが持つコネクションエラー時にリトライするオプションなど(delayed_retryやtransaction_replayなど)を試してみたものの解消することはできませんでした。
試行錯誤の結果、DB 3台によるマルチマスタ構成にすることで解決できました。ただし、マルチマスタ構成の場合でもすべてを解決できるわけではなく、フェイルオーバー時には考慮が必要です。
残された懸念
マルチマスタ構成でも通常Write可能なノードは1つに限られていますが、フェイルオーバーが発生すると別のノードがWrite可能なノードに昇格します。このときレプリケーションが完了してから昇格できれば良いのですが、レプリケーション完了前にレプリケーション対象のレコードへの書き込みが発生していると不整合が起きてしまいます。
- ノード1のレコードAを更新
- ノード1が切り離され「ノード1の更新内容をノード2, 3に同期」する前にノード2が書き込み可能に昇格
- ノード2のレコードAを更新
- 1と3のレコードAの状態に不整合が生まれノード1は自動復旧できない
といった状況です。
このような状況を避けるために
- 共同編集機能の制御
- システムからの更新を追記型にする
など、特定の機能に対しては設計時に考慮が必要になります。
立ち上げ時にどうするか
オンプレで構築する場合は2台か3台かのコストの違いが大きいので、アクセスが少ないうちは従来どおりの2台構成+DBプロキシ(今回はMaxScale)といったDB構成が良いと思いますが、クラウドなどの仮想基盤上に構築するのであればストレージ設計は要注意(合計サイズが1.5倍)ですが、最初から3台構成にするのが良いと感じました。
DB以外の構成は適宜サービスごとに改変して使うものの、先述の構成図の通りで問題ないと思います。
まとめ
完全な無停止運用(サービス停止を一切しない)を目指さず、停止を伴うメンテナンスリリースを何度かに1回計画することを前提とすれば、それほど特殊な構成にすることなく無停止リリースはできそうでした。
今回はオンラインDDLへの対応が進んでいるMySQL系統のMariaDBで検証を進めていましたが、以下の記事でも検証している通り、オンラインDDLに対応していないPostgreSQLでも気をつければ実用上は問題なさそうだったので、PostgreSQL + HAProxy + Patroniなどの構成でも実現できそうな可能性が見えてきました(弊社既存サービスはPostgreSQL採用率が高いのでPostgreSQLが使えると嬉しい)。
引続きHAProxyなどの活用も含めてユーザーの利便性向上を目指していきたいと思います。
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
forms.gleイベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください! rakus.connpass.com
