
はじめに
こんにちは、楽楽精算開発チームの坂田です。
私は今年、楽楽精算における新機能追加プロジェクトにアサインされ、その中で新規アプリケーションの開発を担当する機会をいただきました。
アプリケーションの新規開発は様々な要件を考慮しながら進める必要があり、検討事項は多岐に渡ります。
今回は私自身の振り返りも兼ねて、アプリケーションを設計する際の流れや考え方を共有させていただきたいと思います。
内容はどちらかというと初歩的な物が多く、これから設計にチャレンジしようという方に向けたものとなっています。
この記事が皆さんのアプリケーション開発の一助となれば幸いです。
今回の要件
今回開発に取り組んだ機能の要件はおおよそ以下の通りです。
- 既存システムが外部から日次でファイル取り込みしているデータを、発生の都度リアルタイム取込できるようにしたい
- 取り扱うドメインは単一
- 開発中につき対象となるドメイン等の詳細は割愛
楽楽精算ではあるデータを外部から取り込むためのバッチが稼働しているのですが、日次起動という都合上、お客様の元にデータをお届けするタイミングは一日一回の決められたタイミングとなります。
このデータをよりタイムリーにお客様へお届けするため、データが発生するたびにリアルタイム取込を実現したいというのが今回の背景になります。
またデータのやりとりは B to B の限られたサーバー間でのみ行われます。
非機能要件は以下の通りです。
- 性能要件
- 想定される最大秒間処理回数:1
- 処理完了:3秒以内
通信は限られたサーバー間のみで発生し、頻度もそれほど多くないと言えます。
性能についてはあまり神経質になる必要はなさそうです。
(本当はセキュリティ要件とか運用・保守要件とか色々ありますが、このあたりは表に出せないので割愛)
システム構成を検討する
まずは要件の達成に向けてざっくりとした青写真を描いてみます。
今回のシステムの特徴は、おおよそ以下の通りまとめられそうです。
- リアルタイムのデータ受信
- DBは既存と共通
それぞれの特徴ごとに考えられることを列挙してみます。
- リアルタイムデータ受信
- どのプロトコルを採用するか
- 性能目標は?
- セキュリティは?
- DBは既存と共通
- 既存DB構成
- 既存DBの使用状況
順番に見ていきましょう。
リアルタイムデータ受信
今回は外部サーバーでデータが発生するたびに、こちらのサーバーでデータを受け取れるようにする必要があります。
パッと思いつくだけでも色々なやり方がありそうです。
- HTTPで受信
- どこかにファイルを置いてもらって、SFTPでポーリング
- どこかのキューに入れてもらって、それをサブスクライブ
どれも一長一短あるかと思いますが、今回はHTTPを採用します。
データ送信元でもこちらの処理結果をトラッキングする必要があるため、非同期でデータのやりとりをするよりは、その場でこちら側のステータスを返却できる方が都合が良いからです。
(非同期でもできなくはないですが、ステータスをトラッキングするための仕組みを別で用意するといった一手間が必要になると思います)
今回は単純なデータ受信でセッションのような仕組みも必要ないことから、アプリ自体の構成も自然とREST-APIを採用することになりそうです。
また、性能については性能要件で記載した通りです。
DBは既存と共通
アプリ自体は新規で開発しますが、使用するDBは既存と共通です。
この場合、既存DBの使用状況、特にコネクション数には注意した方が良いと思います。
既存でコネクション上限すれすれの運用をしていた場合、追加のコネクションを貼れない可能性があります。
その際はDB側のコネクション上限を引き上げる等の対策が必要になります。
(DBが稼働しているマシンのスペックとの相談になるので、場合によっては単純に上限を引き上げるだけでは対応が難しいこともあると思います)
今回は幸い、対象DBのコネクションには余裕があるので、この点は問題にならないと考えて良さそうです。
また、DBの構成も重要です。
今回はアプリ一つに対して複数のDBが存在する構成になっており、アプリはデータの内容に応じて登録先となるDBを選択します。
このようにアプリ:DBが1:Nとなっている場合、アプリ側が保持するコネクション数にも注意を払う必要があります。
コネクションが多ければ多いほどアプリが稼働するサーバーのリソースを消費しますし、場合によってはアプリ側のコネクション上限に引っ掛かります。
そのあたりはDBと同様、サーバーのリソースと相談しつつ、コネクション上限を調節することになります。
さらに今回のシステムは少々特殊で、データを受け取った時点では、データを登録すべきDBをすぐに特定できない構成となっています。
このようなマルチテナント構成の場合、データ内部にテナント識別子のようなものがあって、それが直接DB名になっていたり、あるいはそれを元にどこかのデータストアにDB接続先を照会するといった仕組みが一般的かと思いますが、この既存システムは以下のようなアプローチが採用されています。
- 各DB内に保持しているテナント識別子を全て取得する
- アプリが受信した識別子と、1で取得した全識別子を突合する
- 2で合致した識別子を持つDBにデータを登録する
図で表すと概ね以下のようになります。
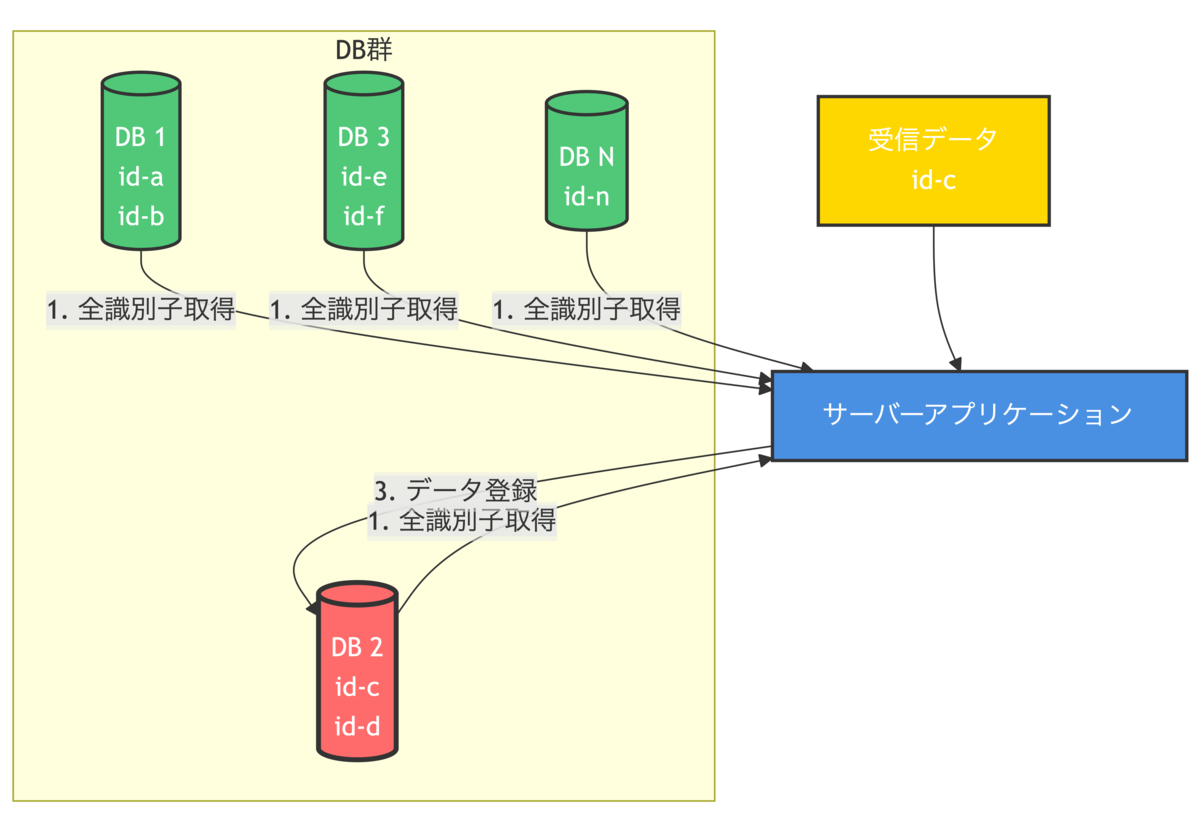
この構成は、「データ登録先を特定するために、一度すべてのDBに接続する必要がある」という点に特徴があります。
みなさんご存知かと思いますが、DB接続はコストの高い処理です。
これが一つや二つなら無視できる程度のオーバーヘッドかもしれませんが、数が増えていくにつれて無視できるものではなくなっていきます。
このシステムに含まれるDBは、現時点で100を超えています。
これはすなわち、100回を超えるDB接続処理がデータ取り込みのたびに実行されているということです。
これだけの回数になると、非常に大きなオーバーヘッドとなります。
既存システムはバッチ処理であり、多少時間がかかっても処理が完了すれば大きな問題にはなりません。
そのため、性能上の懸念はありつつもこの構成で運用されてきました。
しかし、今回作成するアプリはリアルタイムデータ受信用のAPIです。
データ受信頻度は既存システムと比較になりません。
データを受信するたびに100回以上のDB接続処理を繰り返していては、性能要件を達成することは到底不可能です。
そこで今回はDB側にも以下のような構成変更を行います。
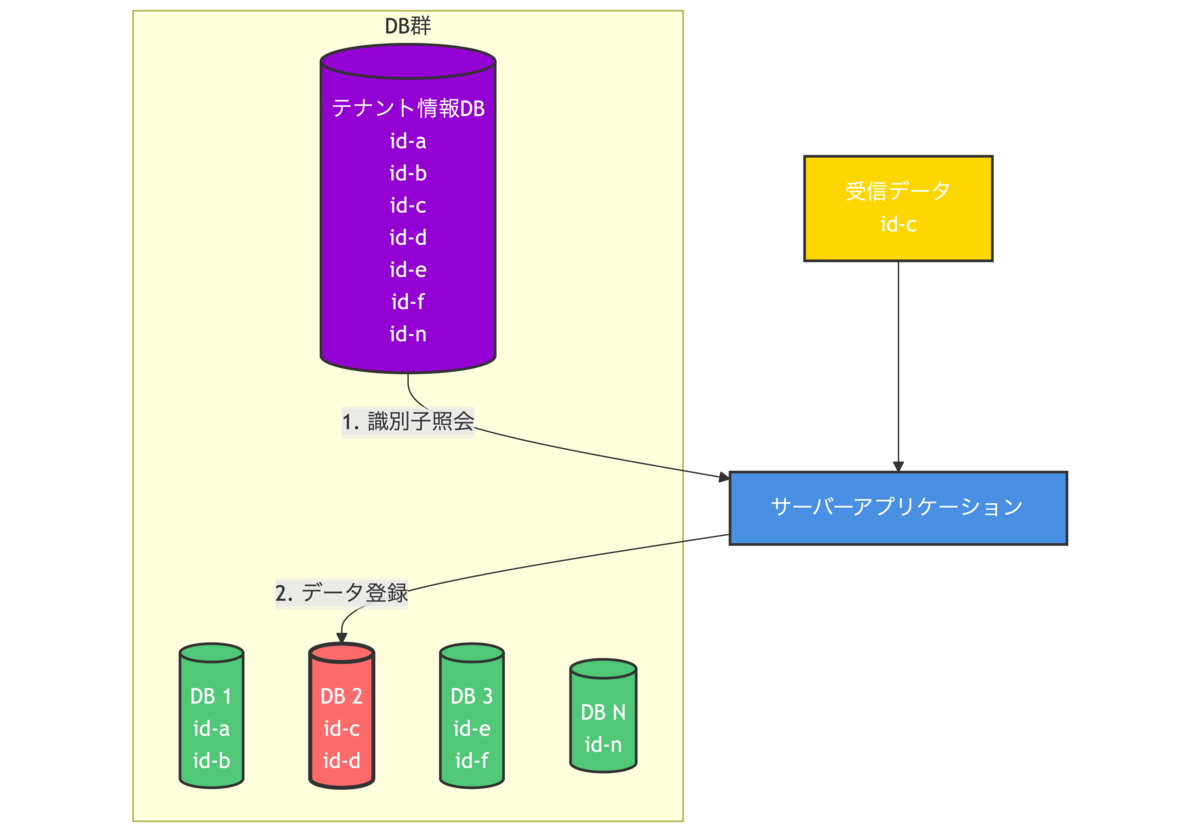
新しく「テナント情報DB」を作成し、そこに各DBに散らばっているテナント識別子を全てコピーして集約します。
(テナント識別子を登録する別のアプリを改修し、各DBとテナント情報DBの情報が常に同期されるようにしています)
新しいアプリはテナント情報DBにテナント識別子を照会することで、全てのDBを参照することなく、最短ルートで適切なDBにデータを登録することができます。
少々回りくどいやり方ですが、今回は既存のデータ取り込みを変更することができないため、やむを得ずテナント識別子のコピーというやり方を選択しました。
(既存も併せて変更できる場合は、各DBのテナント識別子を廃し、テナント情報DBに一本化するのが最も適切だと思います)
アプリのデプロイ先
アプリをデプロイするプラットフォームについても検討が必要です。
(オンプレ or クラウド、サーバーのOS、etc...)
とはいえこのあたりはよほどド新規のサービスでない限りなんらかのプラットフォームがすでに存在していて、そこに載せるのが最善であることが少なくないと思います。
今回の場合は社内で利用可能なKubernetes(k8s)クラスタがすでに存在しているので、そちらにデプロイする方式を採用します。
アプリを設計する
ここまででシステム構成を検討することができました。
あとはこれに当てはめてアプリを設計すればOKです。
これまでの情報をまとめると、アプリの特徴は概ね以下のとおりまとめることができそうです。
- REST-API
- 複数のDBを取り扱う必要がある
これを元に以下のような観点でアプリを設計していきます。
- アプリケーションフレームワーク
- DBアクセスフレームワーク
- トランザクション制御
- DBコネクション
- スレッドプール
- コードアーキテクチャ
- API I/F仕様
- ビジネスロジック
- ログ、メトリクス、トレース
アプリケーションフレームワーク
アプリケーションフレームワークはアプリの基本的な構造となる重要な要素です。
最近だと Spring Boot が主流かと思いますが、Quarkus、Micronaut のようなマイクロサービス系も結構使われてたりすると思います。
弊社でも様々なプロダクトで Spring Boot が活用されています。
社内での普及状況も加味して、今回は Spring Boot を採用したいと思います。
現代のWebアプリケーションに必要な機能は大体カバーされていますし、世の中のナレッジも豊富です。
迷ったら Spring Boot でOKくらいのフレームワークと言えると思います。
REST-APIのフレームワークとしても優秀です。
一応、対抗馬として Quarkus の検討も行いました。
こちらはkube-native、コンテナファーストを謳うフレームワークで、GraalVMのネイティブイメージに早くから対応していた点にも特徴があります。
今回作成するアプリはk8sにデプロイすることになっているので、その点で親和性は高いと言えます。
またDBのコンテナなどを手軽に立ち上げることができるDev Serviceという機能が備わっており、開発環境の構築もかなり快適です。
個人的にはおすすめのフレームワークです。
Spring Boot と比較すると、それほど大きな機能差異はないと言えると思います。
Spring Boot もコンテナ運用は十分可能です。
こういった点と社内外に蓄積されたナレッジを考慮して、Spring Boot を採用することになりました。
この辺りはケースバイケースかと思いますが、今後もメンテナンスしていくことを考えると、ナレッジの有無は重要な判断要素だと思います。
DBアクセスフレームワーク
Java の DBアクセスには JDBC を活用するのが一般的ですが、標準の JDBC API をそのまま業務アプリで採用するのは稀で、何らかのDBアクセスフレームワークを活用することが多いと思います。
これらを活用することで、DBのテーブル構造をJavaオブジェクトとして表現しやすくなり、より簡潔で可読性の高いDBアクセス処理の記述が可能になります。
多くの選択肢が存在しますが、Jakarta EE の仕様に組み込まれている JPA や、独自の仕様を持つ Mybatis、Doma、jOOQ といったものが選択肢としてあげられます。
JPA はDBとJavaオブジェクトの同期を可能にする仕組みで、Javaオブジェクトに対する作成、更新、削除が独自のメモリ空間に反映され、それらをDBと同期するためのSQLを自動で発行します。
(SQLを記述する仕組みもあります)
SQLの記述なしでDBを変更することができるため、適切に設計すれば非常に簡潔で可読性の高いコードを記述することが可能です。
一方でオブジェクトの変更がDBに反映されるまでのメモリ空間上のライフサイクルを適切に把握する必要があり、場合によっては意図しないDB操作を発生させるリスクもあります。
この点で若干ハードルの高い選択肢と言えると思います。
JPA の実装としては、Spring Data JPA や Hibernate 等が挙げられます。
Mybatis、Doma、jOOQ 等は、JavaオブジェクトとDB間のマッピングや、SQL記述方法に独自の仕様を持っているライブラリです。
それぞれの特徴は、ざっくり以下の通りです。
- Mybatis
- SQLをJavaコードやXMLファイルで記述し、それをJavaオブジェクトにマッピングする
- SQL記述の自由度が高い点が魅力で、特に複雑なSQLを必要とする場合に有用
- Doma
- Mybatisと似たような機能に加え、SQL自動生成機能やコンパイル時のSQLチェックといった開発効率化機能を備える
- jOOQ
- SQLをJavaコード上でビルドすることにフォーカスしており、型安全を保ったままDB操作を記述することができる
これらには使い勝手の違いこそありますが、SQLを何らかの方法で表現し、それをプログラム上で明示的に実行するという点で共通しており、ここがJPAとの大きな違いと言えます。
技術選定する際はJPAかどうかが一つの軸に挙げられると思います。
今回は以下のような点を加味して、Mybatisを採用します。
- 個人的に使い慣れている
- 楽楽精算開発チーム内での採用事例が多い
- SQLを柔軟に表現できる
トランザクション制御
トランザクションの設計はDB操作に関連する重要な要素です。
ここではプログラムのどの単位をDBトランザクションの区切り(トランザクション境界)とするかを検討します。
例えばあるAPIの中に大きく分けてA、B、Cの三つの処理が含まれているとします。
これに対し、いくつかトランザクション境界のパターンを考えてみます。
- すべて一つのトランザクションとする
- A、B、Cすべての処理が成功した場合のみコミットされる
- いずれか一つでも失敗すれば、すべてのDB操作がロールバックされる
- 「A、B」と「C」で分ける
- A、Bは両方成功しないとコミットされない
- Cが失敗しても、A、Bはロールバックされない
- すべて個別のトランザクションとする
- いずれかの処理が失敗しても、他のトランザクションはロールバックされない
このように、どこにトランザクション境界を置くかによって、最終的なDB操作の結果が変わってきます。
特にいくつかの単位に分ける場合、何らかの処理が失敗しても、すでにコミットされたトランザクションはロールバックできないという点に注意が必要です。
もし全ての処理が常に同期している必要があるにも関わらず、Cの結果のみコミットされないといった場合、Cの結果が欠落した中途半端なデータが出来上がります。
またエラーが発生したトランザクションの後にも別のトランザクションを発行する処理が実装されている場合、エラーとなった時点で処理全体を止めるのか、それとも処理を継続して別のトランザクションを開始するのかといった判断も必要になります。
例えば処理の実行結果をDBに残すと言った場合、処理の成否に関わらず履歴が登録される必要があります。
この場合、先行するトランザクションが失敗した場合も、履歴登録処理は確実に実行されるよう設計されているべきです。
以上のようなことを踏まえて、今回のアプリケーションにおけるトランザクション設計を考えてみます。
システム構成でも述べた通り、一回の処理で二つのDBに接続する必要があります。
そのため、これらを一つのトランザクションとするか、それともDBごとにトランザクションを分離するかという判断が必要になってきます。
複数DBを一つのトランザクションとして扱う場合、2フェーズコミットのような仕組みが必要になります。
これは各DBに対する操作をコミット前の状態で待機させ、全てのDB操作が成功したタイミングでコミットされます。
(いずれかが失敗した場合はすべてロールバックされます)
複数DB間でデータの一貫性を保証できる一方、どこかの処理が遅延すればそれだけ多くのDBをロックすることになり、パフォーマンス上の影響が懸念されます。
こういった影響を最小限に抑えるための適切な設計が必要になるため、ハードルの高い選択肢と言えます。
まずはこれらに対するトランザクションを一つにまとめる必要があるか判断します。
今回の場合、「テナント情報DBからテナント情報を取得→取得した情報を元にいずれかのDBに登録」という流れで処理が行われます。
テナント情報DBへの接続は読み取り専用になるため、トランザクションについてはそれほど意識する必要はなさそうです。
これ以降の処理で何らかのエラーが発生したとしてもテナント情報DBの状態には一切影響がないため、パフォーマンス上の影響も加味して、2フェーズコミットを採用するメリットはあまりないと考えられます。
そのため、今回は各DBアクセス単位でトランザクション境界を作成する設計とします。
DBコネクション
コネクションプール
先述の通り、DB接続は比較的コストの高い処理です。
あまりにも頻繁に行っていると、CPU使用率の増加でアプリケーション、ひいてはサーバー全体のパフォーマンスに悪影響を及ぼす恐れがあります。
それを避けるために一般的な手段がコネクションプールです。
これは一度開いたDB接続をプールしておき、次回以降の処理で使い回すというものです。
これによりDB接続の頻度を下げ、一回の処理あたりのオーバーヘッドも下げることができます。
Spring BootはデフォルトでHikariCPによるコネクションプールが備わっているので、特に意識しない限りこれを使うのが一般的かと思います。
一方、プールされたDB接続の個数が増えるにつれ、メモリ使用量も増えていきます。
アプリ:DBの数が1:1のような構成であればそれほど大きな問題になりませんが、これが1:Nとなるとどうでしょうか。
今回のシステム構成では一つのアプリケーションが100個を超えるDBにアクセスするため、コネクションプールも相当数確保する必要があります。
(一つのDBに対するコネクションは一つとは限らないので、これを二つ三つと増やすにつれて、全体のプール数も増加していきます)
この場合、そもそもコネクションプールが必要かどうかという点を確認する必要があります。
その際の判断基準の一つが性能要件です。
冒頭を振り返ると、性能要件は以下のようになっていました。
- 性能要件
- 想定される最大秒間処理回数:1
- 処理完了:3秒以内
この程度であれば、コネクションプールがなくても性能要件は十分達成可能と言えます。
既存のように全DBにいちいち接続する必要がある場合はコネクションプールが必須と言えますが、今回はその点も改善されています。
以上のことから、今回コネクションプールは採用しない方針とします。
ここからさらに流量が増えてきた場合は、コネクションプールの導入を検討した方が良いと思います。
そのあたりはケースバイケースなので、早めにPoCを作って性能検証を行い、コネクションプールの有無でどの程度のパフォーマンスが出るか確認した上で判断するのが良いと思います。
DB接続の上限
コネクションプールを活用するかどうかに関わらず、同時に使用できるDB接続の上限を管理する必要があります。
この上限を超えるDB接続はその時点でペンディングとなり、別のDB接続が終了するまで待機することになります。
Spring Boot で Hikari CP を採用している場合、デフォルトの最大値は10です。
今回のアプリケーションでもこの値で性能検証の結果が良好だったことから、上限を10に設定しています。
もしここで性能劣化等の現象が発生した場合は、この値を調節する必要があります。
値が小さすぎるとDB接続待ちが発生しやすくなりますし、逆に大き過ぎれば、同時アクセス数が増えるにつれてメモリ使用量を圧迫すると同時に、接続の切り替えに伴うコンテキストスイッチも増えていきます。
いずれの場合も処理の遅延を招き、DB処理の待ち行列がどんどん長くなっていくことが予想されます。
値の決定には以下のようなことを考慮する必要があります。
- 性能要件(予想される流量)
- アプリケーションが稼働するサーバーのスペック
- DBが稼働するサーバーのスペック
明確な基準については諸説あると思いますが、サーバーのCPUコア数は代表的な判断基準と言えると思います。
一般的な同期処理アーキテクチャを採用するアプリケーションは、DB処理中にCPUコアを占有します。
そして、CPUはコア数を超える処理を同時に行うことはできません。
そのため、コネクション数を多めに設定したとしても、同時実行可能な処理数はコア数で頭打ちとなり、それを超える分はコアが解放されるまで待ち状態となります。
待ちが多くなればなるほどメモリ使用量増加と頻繁なコンテキストスイッチを誘発するので、コネクションの増やしすぎには特に注意した方が良いと思います。
実際の設定値については、CPUコア数を軸に据えて調節しながら、性能検証を重ねて適切な値を割り出すというアプローチが良いと思います。
スレッドプール
コネクションプールはDB接続に対してのものですが、スレッドプールはサーブレットのスレッドをプールする仕組みです。
リアクティブなAPIを除いて、世の中で稼働するJavaベースのWebアプリケーションは、大部分がサーブレットです。
Spring Boot も例外ではありません(Web Fluxを採用した場合を除く)。
サーブレットはリクエストを受信するたびに、リクエスト専用のスレッドを確保します。
スレッド作成はDB接続と同様にコストの高い処理なので、リクエストのたびにスレッドを作成していては処理の遅延に繋がります。
それを避けるため、作成されたスレッドをプールしておき、リクエスト受信時に使い回す仕組みがスレッドプールです。
Spring Boot のデフォルト値は200です。
こちらも性能検証で問題がみられなかったことから、この値を採用しています。
もし問題が見つかった場合は、DB接続と同様、CPUコア数を軸に調整するのが良いと思います。
また Virtual Thread も選択肢の一つです。
これは Java21 で登場した新しいスレッドで、DB接続などのI/O中にCPUがブロッキングされないという点に特徴があります。
詳しい説明は省きますが、例えばDBサーバー側で処理に時間がかかっているような場合、従来のスレッドではCPUを占有し続けるため、他のスレッドはこれが解放されるまで待ち状態となります。
これが Virtual Thread に置き換わると、DB処理中にCPUの占有を解除し、他のスレッドがCPUを使用できる状態を作り出すことができます。
これにより、I/O待ちが多く発生するようなアプリケーションにおいてCPUの能力をより効率的に活用し、従来よりも多くのスレッドを同時に扱うことができるようになります。
従来のスレッドを置き換えるだけでリアクティブプログラミングのような恩恵を教授できるという点が画期的で、モダンJavaの中でも注目を集めている技術です。
(今回はパフォーマンス的にそれほどシビアなユースケースではなかったことから採用は見送りました)
コードアーキテクチャ
例えばMVCという言葉はかなり一般的かと思いますが、それに類するものがコードアーキテクチャです。
ここではソースコードの構成(レイヤやクラス設計等)を検討します。
これの良し悪しがアプリケーションのメンテナンス性の良し悪しに直結すると言っても過言ではなく、開発速度の担保や安定的な運用に欠かせない重要な要素です。
最近はドメイン駆動設計(DDD)の考え方がずいぶん浸透してきたように感じます。
これはアーキテクチャの中心にドメインを据える考え方で、ドメインの振る舞いや状態に応じてユースケースを組み立てていきます。
それと同時に、DB接続のようなインフラ層の実装をドメインから分離することで、インフラ層の仕様に左右されることなく、ドメインの振る舞いに集中できるようになります。
詳細を語ると長くなるので省きますが、ドメインの振る舞いに集中する考え方は一度慣れると非常にわかりやすく、個人的にもおすすめの手法です。
アーキテクチャの決定には取り扱うドメインや業務要件が大きく関わってきますが、要件が単純な場合はMVCのような三層構造でも良いと思います。
ドメイン駆動設計を取り入れたアーキテクチャはMVCと比較すると複雑な傾向があるので、要件によっては過剰な設計となることも考えられます。
今回作成するアプリケーションは単一のドメインを扱う非常にシンプルな要件です。
この点だけ見るとMVCでも良さそうですが、既存のDB構造と今回取り扱うドメインの構造に微妙なギャップがあり、DB構造にドメインが引きずられることを避ける必要がありました。
ドメイン層とインフラ層を分離できるドメイン駆動の考え方はこの点で都合が良く、今回はこれをよく取り入れているオニオンアーキテクチャを採用しました。
(オニオンアーキテクチャはドメイン駆動設計を取り入れた設計手法の一つで、この他にクリーンアーキテクチャ等が存在します)
API I/F仕様
Web-APIの場合、リクエストやレスポンスの形式を定める必要があります。
業務要件に応じて、以下のような観点で設計を行います。
- リクエスト
- URL
- HTTPメソッド
- ヘッダ
- パラメータの種類や形式
- レスポンス
- HTTPステータス
- ヘッダ
- ボディ
今回のアプリケーションでは、REST-APIを採用しています。
そのため、URLで操作対象のドメインを、HTTPメソッドで操作内容ををそれぞれ表現する必要があります。
例えば対象のドメインが「hoge」の場合、URLはhttp://xxx.yyy.zzz/hogeとなります。
このドメインを取得する場合、HTTPメソッドは「GET」となります。
これが新規作成になるとHTTPメソッドが「POST」となり、更新では「PUT」、削除では「DELETE」となります。
URLのhttp://xxx.yyy.zzz/hogeは常に一定で、パスパラメータで操作対象データのユニークキーを指定したり、クエリパラメータで検索条件を設定する場合もあります。
またPOSTやPUTの場合、リクエストボディに登録または更新内容を設定することになります。
今回は要件が単一ドメインの登録のみのため、POSTメソッドに対するAPIエンドポイントを設計すればOKです。
こういったAPIではリクエストボディにJSON形式のデータを設定するのが一般的ですが、今回もそれに倣った設計とします。
Spring Boot ではJSON形式のリクエストボディをJavaオブジェクトにマッピングする仕組みがデフォルトで備わっており、その点でも親和性が高いです。
またREST-APIの仕様書についてはOpenAPIのフォーマットが一般的なので、特にこだわりがなければそちらを採用するのが良いと思います。
(共通言語なので社外とのやりとりもスムーズです)
ビジネスロジック
業務要件をプログラムで直接表現するのがビジネスロジックです。
この部分は要件によってまちまちなのですが、少なくともアプリケーションフレームワークやトランザクション制御、コードアーキテクチャなどから逸脱した設計にならないよう注意する必要があります。
(今回の要件はあまり表に出せないため、詳細は割愛します。)
ログ、メトリクス、トレース
これらはアプリケーションの運用にあたって必要な要素です。
ログはアプリケーションに対するアクセス状況や処理結果等をテキストで出力することで、外部からこれらを確認することができます。
特にエラー発生時に出力されるスタックトレースといった情報は、本番環境のデバッグにおける重要な情報源となります。
また要件によっては機能の実行回数や利用者数を集計したいといった場合があり、それらをログで実現することもあります。
Spring Boot の場合はデフォルトで Logback が有効化されているため、特にこだわりがなければそちらを利用するのが良いと思います。
また Grafana Loki のようなログ集計システムを使用する場合、ログを JSON フォーマットで出力することでラベルごとの集計が容易になります。
メトリクスはサーバーのCPU使用率やメモリ使用率、Javaプロセスのヒープ使用率、GC発生状況等を監視するために取得する情報です。
これらを適切に取得し監視することで、サーバーそのものやプロセスの異常を検知することができます。
これを実現するツールとしては OSS の Prometheus が有名です。
Spring Boot では Micrometer の Prometheus 用エンドポイントを有効化することで、Prometheus が必要としている情報を簡単に取得することができます。
Prometheus が利用できる環境では、これを活用するのが良いと思います。
トレースは処理の流れを追跡するための仕組みです。
処理全体の開始から終了までをトレース、その中の任意のステップ(メソッド呼び出しやDBアクセス等)をスパンとして記録します。
スパンごとの処理時間を計測することでパフォーマンス上のボトルネックを特定したり、エラー発生までの処理内容を確認することで原因特定に役立てるといった活用方法が考えられます。
これはシステム間を跨ぐような処理でも一つのトレースとして扱うことができるため、複数のマイクロサービスが協調して動作する分散システムのような構成では特に有用です。
これを実現するための有名な OSS として OpenTelemetry があります。
Spring Boot には OpenTelemetry と連携する仕組みが用意されているので、これを活用するのが良いと思います。
今回作成したアプリケーションでは、以下の構成を採用します。
(収集および可視化ツールは社内で標準化されたプラットフォームが存在するので、そちらに合わせています)
| テレメトリー種別 | 出力 | 収集 | 可視化 |
|---|---|---|---|
| ログ | Logback (JSON形式出力には logstash-logback-encoder を使用) | Grafana Loki | Grafana |
| メトリクス | Micrometer Prometheus | Prometheus | Grafana |
| トレース | OpenTelemetry Java Agent | Grafana Tempo | Grafana |
まとめ
新規アプリケーション設計の流れと考え方を振り返ってみました。
ここに書かれているだけでも多くの検討事項がありますが、これ以外に書ききれなかった項目もありますし、書いてある内容もまだまだ掘り下げられると思います。
それだけアプリケーション設計は考えることが多く、奥が深い作業です。
今回のアプリケーションは比較的単純な構造でしたが、改めて振り返るとそれなりに時間のかかる作業だったと思います。
一方で大変なだけでなく、ゼロからモノを作り上げる楽しさもあります。
既存サービスの開発ではアプリケーションを新規で作成するような機会はそれほど多くないので、エンジニアとしては大変貴重な機会をいただけたと思います。
冒頭でも述べた通りですが、今回の投稿がこれから設計挑戦する皆さんの一助となれば幸いです。
