
目次
1. はじめに
こんにちは!SRE課のモリモトです。
ArgoCDはk8sエコシステムの1つであり、GitOps基盤として多くの会社で採用されています。 ラクスのk8s環境でも採用しており、私が所属するSRE課でも運用しています。
しかし、私を含め、Argo CDの内部構造を十分に理解しないまま使っている方も多いのではないでしょうか。
そこで本記事では、ややニッチなテーマではありますがArgoCDのApplication Controllerに特化して、ソースコードをベースに内部実装を解説してみたいと思います。
前提条件
- ArgoCDの全体アーキテクチャや各コンポーネント間の繋がりについては、すでにある程度理解している前提で解説します。
- もしあまり理解できていないって方がいらっしゃいましたら、他の方のブログではありますが↓が大変わかりやすいのでまずこちらを読んでいただければと思います!
免責
- 本記事の内容は
v3.2.1時点の情報に基づいています。 - 一部、端折って解説している部分が多々あります。正確な挙動は実際にソースコードをご確認ください。
- 可能な限り正確な記述を心がけていますが、誤りがあればご指摘いただけると幸いです。
2. Application Controllerの役割
まずはArgoCD全体像における立ち位置をおさらいします。
ArgoCDにおいて、Application Controllerはまさに「心臓部」と言えるコンポーネントです。 以下2つの状態を継続的に監視・比較し、差異が検出された場合、設定に応じて同期を実行します。
- GitHubリポジトリ上のマニフェストが定義する「あるべき姿 (Desired State)」
- k8sクラスタ上の「現在の姿 (Live State)」
3. Application Controllerのアーキテクチャ
アーキテクチャ構成図は以下のようになります。(だいぶ簡略化しています)
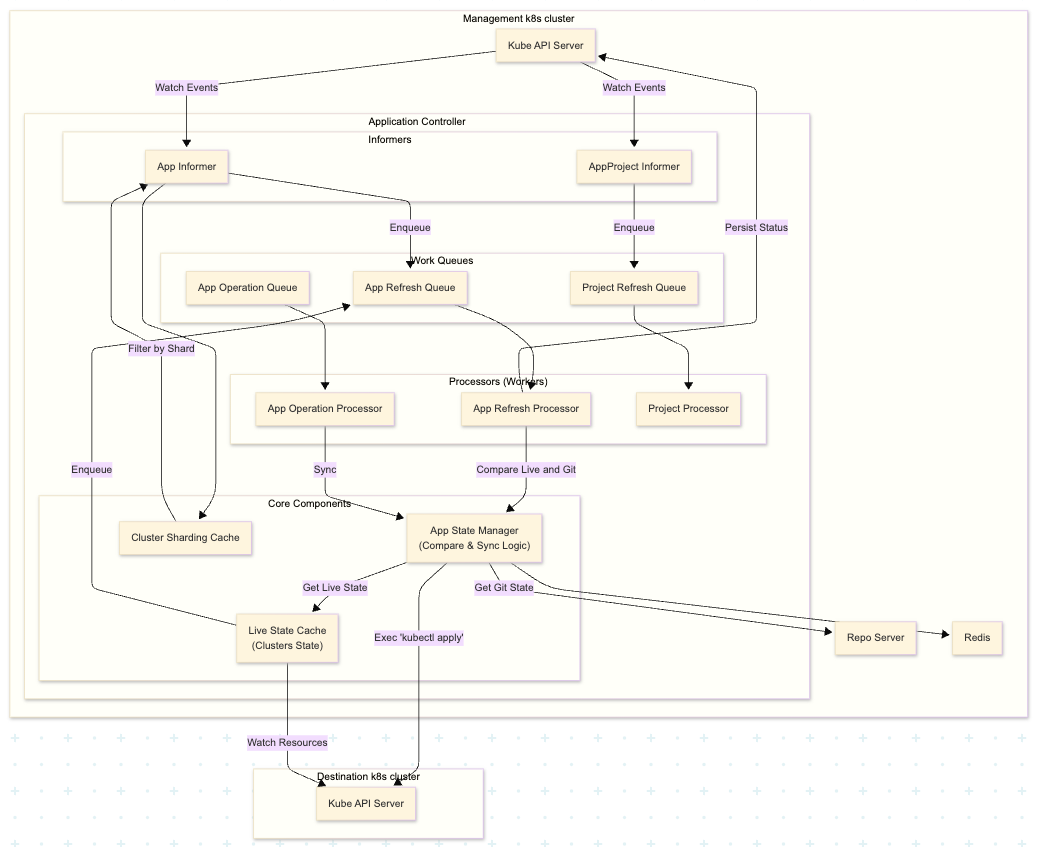
主要なコンポーネントには以下のようなものがあります。
| カテゴリ | コンポーネント名 | 役割・説明 |
|---|---|---|
| Work Queues | App Refresh Queue | アプリケーションの状態を確認し、ステータス更新(Refresh)を行うイベントのためのWorkqueue |
| App Operation Queue | k8s クラスタに対して実際の同期操作(Sync)を行うイベントのためのWorkqueue | |
| Project Refresh Queue | Project設定の変更を反映するイベントのためのWorkqueue | |
| Processors | App Refresh Processor | App Refresh Queueからイベントを取得し、アプリケーションの状態確認とステータス更新(Refresh)を実行するWorker |
| App Operation Processor | App Operation Queueからイベントを取得し、k8sクラスタへの同期操作(Sync)を実行するWorker |
|
| Project Processor | Project Refresh Queueからイベントを取得し、Projectの設定変更を反映するWorker |
|
| Core Components | App State Manager | Controllerの脳にあたる部分。GitHub上のマニフェストとクラスタのLive Stateを比較したり、実際にkubectl applyによる同期を実行したりする内部コンポーネント |
| Live State Cache | 管理対象クラスタ内の全リソース情報をメモリ上に保持する内部のキャッシュコンポーネント | |
| Cluster Sharding Cache | コントローラーが複数台構成の場合に、自インスタンスがどのクラスタを担当すべきかのマップを保持する内部コンポーネント |
Application Controllerは、一般的なKubernetes Controllerと同様に、「イベントをためるWorkqueue」と「実際に処理を行うWorker(goroutine)」を内部に持っています。 Applicationリソースの変更などのイベントが発生すると、まずこのWorkqueueにタスクが積まれます。 そして、WorkerがWorkqueueからタスクを取り出して実際に処理を行います。
ここで重要なのが、Refresh処理とSync処理がそれぞれ別のWorkqueue、Workerに分かれている点です。 これにより、特定のアプリケーションの同期処理(Sync)に時間がかかっても、他のアプリケーションのステータス更新(Refresh)がブロックされることを防いでいます。
例えば、大規模なリソース作成やPre-Sync Hookの待ちによってSync処理が長時間ブロックされた場合でも、 別レーンで動作するRefresh処理は影響を受けず、UI上のアプリケーション状態は常に最新に保たれます。 また、負荷状況に応じて、それぞれの並列数(Processor数)を個別にチューニングできるというメリットもあります。
Application Controllerの起動処理(ctrl.Run())
Runメソッドは、Application Controllerのメインエントリーポイントであり、コントローラーの起動、初期化、そして各Worker(goroutine)の起動を行います。
重要な点はワーカーの起動です。
以下のように、statusProcessorsやoperationProcessorsで定義した数だけWorker(goroutine)を起動し、processAppRefreshQueueItem()やprocessAppOperationQueueItem()の中でキューに積まれたタスクを実行していきます。
App Refresh Processor
アプリケーションの比較・ステータス更新を担当。
for i := 0; i < statusProcessors; i++ { go wait.Until(func() { for ctrl.processAppRefreshQueueItem() { } }, time.Second, ctx.Done()) }
App Operation Processor
実際の同期処理(kubectl apply)を担当。
for i := 0; i < operationProcessors; i++ { go wait.Until(func() { for ctrl.processAppOperationQueueItem() { } }, time.Second, ctx.Done()) }
該当箇所
Reconciliation Loop(内部メカニズム)
ArgoCDの「同期」は、大きく分けてRefreshとSyncOperationの2つのフェーズで構成されています。
Phase 1: Refresh
- イベントの検知: 「Applicationリソースの変更」や「監視対象リソースの変更」等のイベントを検知し、
App Refresh Queueにアプリケーションキーをエンキュー - キューからの取得:
App Refresh Processorが、App Refresh Queueから処理対象のアプリケーションキーを取得。 - アプリケーションの取得:
App InformerのキャッシュからApplicationリソースを取得。 - 状態の取得:
App State Managerが、以下2つの状態を取得。- Target State (Git):
Repo Serverからマニフェストを取得。 - Live State (K8s):
Live State Cacheから現在のクラスタ上のリソース状態を取得。
- Target State (Git):
- 状態の比較:
App State Managerが、取得した2つの状態を比較しステータスを計算。- Syncステータス:
SyncedかOutOfSyncかを判定。 - Healthステータス: リソースが健全(Healthy)かどうかを判定。
- Syncステータス:
- AutoSync判定: ApplicationリソースがAutoSync設定で、かつ
OutOfSyncの場合、Applicationリソースの.Operationフィールドをセット。(.Operationフィールドが同期処理のトリガーになる) - ステータス更新: Applicationリソースの
SyncステータスとHealthステータスをセットし、Kube API ServerにPatchリクエストを送信して永続化。 - Refresh処理が完了した直後に、必ず
appOperationQueueにアプリケーションキーをエンキュー。
8については少し補足で、以下のようにworkerの処理にdeferでApp Operation QueueにappKeyをエンキューするようになっています。
defer func() { if r := recover(); r != nil { log.Errorf("Recovered from panic: %+v\n%s", r, debug.Stack()) } // App Operation QueueにappKeyをエンキューする ctrl.appOperationQueue.AddRateLimited(appKey) ctrl.appRefreshQueue.Done(appKey) }()
該当箇所
Phase 2: Sync Operation
- キューからの取得:
App Operation Processorが、App Operation Queueから処理対象のアプリケーションキーを取得。 - アプリケーションの取得:
App InformerのキャッシュからApplicationリソースを取得。 - 最新状態の取得: 操作を二重に行ったり古い情報で判断したりするのを避けるため、直接
Kube API Serverから最新のApplicationリソースを取得。 - 同期処理の実行: Applicationリソースの
.Operationフィールドがnilではない場合、kubectl apply相当の処理を実行してK8sクラスタに変更を適用。 - 完了後のリフレッシュ: 操作が正常に完了した場合、UI上の表示(SyncステータスやHealthステータス)を即座に最新にするために
App Refresh Queueにアプリケーションキーをエンキューし、強制的なリフレッシュをトリガー。
該当箇所
このように、複数のコンポーネントが相互作用することで、同期操作を実現しています。
4. Shardingの仕組み
Application数や管理対象クラスタ数が増加すると、単一の Application Controller Pod では Refresh / Sync のスループットが頭打ちになります。 Processor 数を増やすだけでは限界があり、このスケール問題を解決するために導入されているのがApplication Controller の Sharding(水平分割)です。
弊社でもApplication ControllerのShardingを行っています。
このShardingの中身について見ていきます。
Shardingとは?
k8s Controller における Shardingとは、複数のControllerで管理対象リソースを分担して処理する手法のことです。
通常、Controllerは単一インスタンスで全リソースをwatch/reconcileしますが、Shardingでは何らかの値を元に管理対象を複数Controllerに分割し、各Controllerは「自分のshard」に属するリソースのみを処理します。
これにより、以下のようなメリットがあります。
- 大規模クラスタでのスケーラビリティ向上
- Reconcile負荷・Kube API Server負荷の分散
ArgoCD Application ControllerでもShardingを設定することができます。
※ より詳細が気になる方は公式ドキュメントをご参照ください argo-cd.readthedocs.io
Shardingのコアメカニズム
ArgoCDのShardingの大きな特徴は、Application単位ではなく「デプロイ先クラスタ単位」で担当シャードが決まる点です。 つまり、「あるクラスタAにデプロイされる100個のApplication」は、全て同じ1つのControllerシャードによって処理されます。
Application ControllerのメインのReconcileループでは、各Applicationを処理すべきかどうかをcanProcessApp()メソッドで判断しています。
func (ctrl *ApplicationController) canProcessApp(obj any) bool { // ... (省略) ... // Applicationのデプロイ先クラスタ情報を取得 destCluster, err := argo.GetDestinationCluster(context.Background(), app.Spec.Destination, ctrl.db) if err != nil { return ctrl.clusterSharding.IsManagedCluster(nil) } // そのクラスタが自身の担当かどうかをチェック return ctrl.clusterSharding.IsManagedCluster(destCluster) }
ここで呼び出されているIsManagedCluster()メソッドが、割り当て判定の核心部分です。
// IsManagedCluster returns whether or not the cluster should be processed by a given shard. func (sharding *ClusterSharding) IsManagedCluster(c *v1alpha1.Cluster) bool { sharding.lock.RLock() defer sharding.lock.RUnlock() if c == nil { // nil cluster (in-cluster) is always managed by current clusterShard return true } clusterShard := 0 // Shardsマップには、各クラスタに対して割り当てられたシャード番号が格納されている if shard, ok := sharding.Shards[c.Server]; ok { clusterShard = shard } else { log.Warnf("The cluster %s has no assigned shard.", c.Server) } // クラスタに割り当てられたシャード番号が、自身のシャード番号(sharding.Shard)と一致するか確認 return clusterShard == sharding.Shard }
このように、ApplicationそのもののID等で判定しているのではなく、「そのApplicationが属するCluster」がどのシャードに割り当たっているかを確認していることがわかります。
ArgoCDで選択できるシャーディングアルゴリズム
では、その「各クラスタが割り当てられるシャード」はどのように決定されるのでしょうか。 ArgoCDでShardingする際に利用できるアルゴリズムは以下の3つです。
- Legacy
- Round Robin
- Consistent Hashing
Legacy
デフォルトで選択される 従来型のアルゴリズムです。
このアルゴリズムは「クラスタID」を基に、そのクラスタを担当すべき「シャード番号」を決定します。
具体的には、FNV-1aハッシュアルゴリズムを使用してクラスタIDを数値化し、
その数値をControllerのレプリカ数で割った余りを計算して担当シャードを決定します。
特徴
| 項目 | 内容 |
|---|---|
| 計算式 | hash(cluster.ID) % replicas |
| 特徴 | 単純な剰余計算のため、ハッシュ結果の偏り次第では特定のシャード(レプリカ)にクラスタが集中する可能性がある。均等分散は保証されない。 |
| スケーリング時の影響 | レプリカ数が変わると計算結果が大きく変化するため、スケールアウト/イン時に多数のクラスタ担当が入れ替わる。そのため再配置コストが高い。 |
該当箇所
Round Robin
このアルゴリズムは、均等な分散を保証するアルゴリズムです。
全クラスタをクラスタIDでソートしたリストを作成し、クラスタIDをキーとしたインデックスマップを作成します。 そして、そのマップ(各クラスタの順位)に基づいて担当シャードを割り当てます。
具体例
以下のように、全クラスタをIDでソートし、各クラスタに連番のインデックスを付与します。
そして、インデックス % レプリカ数 で担当シャードを決定しています。
| クラスタID | Index | 計算式 | 担当シャード |
|---|---|---|---|
| cluster-a | 0 | 0 % 3 = 0 | Shard 0 |
| cluster-b | 1 | 1 % 3 = 1 | Shard 1 |
| cluster-c | 2 | 2 % 3 = 2 | Shard 2 |
| cluster-d | 3 | 3 % 3 = 0 | Shard 0 |
| cluster-e | 4 | 4 % 3 = 1 | Shard 1 |
特徴
| 項目 | 内容 |
|---|---|
| 計算式 | clusterIndex % replicas(clusterIndexはソート済みリスト内の順位) |
| 特徴 | 各シャードに割り当てられるクラスタ数が均等になることが保証される。Legacyと異なり、偏りが発生しない。 |
| スケーリング時の影響 | クラスタの追加・削除があるとソート順が変化し、多くのクラスタで担当シャードが再計算される。結果として、クラスタリストの変更時にシャッフルが発生しやすい。 |
該当箇所
Consistent Hashing
このアルゴリズムは、ほぼ均等な分散を実現しつつ、スケーリング時の影響を最小化するアルゴリズムです。
Consistent Hashing with Bounded Loads(負荷制限付き一貫性ハッシュ)アルゴリズムを使用し、他のアルゴリズムと異なり担当するクラスタのアプリケーション数も考慮したクラスタ割り当てを行います。
このあたりは自分自身も理解しきれていない部分があるので、ふんわりとした解説になってしまいますが、、、シャード割り当てのポイントは以下です。
- 各シャードをリング上に配置する(コンシステントハッシングの考え方)
- 負荷上限を考慮して、最も負荷の低いシャードにクラスタを割り当てる
- クラスタ割り当て後、そのクラスタのアプリケーション数分だけシャードの負荷を更新
func createConsistentHashingWithBoundLoads(replicas int, getCluster clusterAccessor, getApp appAccessor) map[string]int { clusters := getSortedClustersList(getCluster) appDistribution := getAppDistribution(getCluster, getApp) // クラスタごとのアプリ数 consistentHashing := consistent.New() // 各シャードをハッシュリングに追加 for i := 0; i < replicas; i++ { consistentHashing.Add(strconv.Itoa(i)) } for _, c := range clusters { // 最も負荷の低いシャードを取得 clusterIndex, _ := consistentHashing.GetLeast(c.ID) // シャードにクラスタを割り当てる shardIndexedByCluster[c.ID] = clusterIndex // シャードの負荷を更新(アプリ数を加算) appsIndexedByShard[clusterIndex] += appDistribution[c.Server] consistentHashing.UpdateLoad(clusterIndex, appsIndexedByShard[clusterIndex]) } }
これにより、クラスタ数だけでなくアプリケーション数まで考慮して、シャードへのクラスタ割り当てが可能になります。 また、コンシステントハッシングアルゴリズムを利用することで、クラスタの増減が発生しても再割り当てのコストを抑えることができます。
特徴
| 項目 | 内容 |
|---|---|
| 計算方法 | Consistent Hashingアルゴリズム + 負荷上限による再配置 |
| 特徴 | 各シャードに割り当てられるクラスタ数がほぼ均等になる。さらに、クラスタ単位ではなくアプリケーション数も考慮するため、実際の処理負荷がより均等化される。 |
| スケーリング時の影響 | レプリカ数やクラスタ数が変化しても、影響を受けるのは一部のクラスタのみ。Consistent Hashingの特性により、再配置コストが最小限に抑えられる。 |
該当箇所
シャードIDの決定
最後に、各Application ControllerのPodはどのようにして「自分はシャードN番である」と認識するのかについて触れておきます。 これには大きく分けて2つのパターンがあります。
パターンA: StatefulSet (静的割り当て)
デフォルトの設定で利用している場合、Application ControllerはStatefulSetでデプロイされ、シャード番号はPodのホスト名から推論されます。
InferShard()メソッドがそのロジックです。
func InferShard() (int, error) { hostname, err := osHostnameFunction() if err != nil { return -1, err } parts := strings.Split(hostname, "-") // ... (省略) ... // ホスト名の最後のハイフンの後ろの数字をパースする // 例) argocd-application-controller-0 → 0 shard, err := strconv.Atoi(parts[len(parts)-1]) // ... (省略) ... return int(shard), nil }
非常にシンプルで、argocd-application-controller-0ならシャード0、というようにPod名から決定されます。
パターンB: Deployment (動的割り当て)
Dynamic Cluster Distribution機能を利用している場合、StatefulSetではなくDeploymentでデプロイされるためホスト名がランダムになり、パターンAの方法は使えません。
この場合、ConfigMapを使った動的な割り当てとハートビートにより、各Controllerが自律的に担当シャードを決定します。
- Controllerは、起動時および定期的に
argocd-controller-shard-cmConfigMapを確認します。 - 自身がまだシャードを担当していない場合、「空いているスロット」 または 「ハートビートがタイムアウトしているスロット」 を探します。
- 条件に合うスロットがあれば、そこに自分(Pod名)を登録して担当者となります。
- 担当が決まった後は定期的に
HeartbeatTimeを更新し、自分が生存していることを知らせます。他のControllerはこの時間が古くなると、そのシャードの担当がダウンしたとみなしてスロットを奪い取れるようになります。
この仕組みにより、Argo CDはStatefulSetに依存せずとも、各コントローラが一意なシャードIDを持ち、役割分担を行うことができます。
5. まとめ
今回は、ArgoCDのApplication Controllerに特化し、内部の仕組みをソースコードを読み解きながら整理しました。 まだ理解しきれていない部分が多々ありますが、少しは理解が深まった気がします。
AIの進化でコードリーディングが格段にしやすくなりましたね。私もかなり助けられました。
長くなりましたが、最後まで読んでくださりありがとうございました!
